بیشینه هموار
در ریاضیات تابع بیشینهٔ هموار (به انگلیسی: softmax function) یا تابع نمایی نرمالسازیشده (به انگلیسی: normalized exponential function)[1]:198 تعمیم تابع لجستیک است. تابع بیشینهٔ هموار یک بردار -تایی از اعداد حقیقی مانند را به عنوان ورودی دریافت میکند و بردار -تایی از مقادیر حقیقی را به عنوان خروجی میدهد که جمع مولفههای آن ۱ میشود. ضابطه تابع به شرح زیر است:




for j = 1, …, K.

خروجی تابع بیشینههموار، در نظریه احتمالات میتواند برای نمایش یک توزیع رستهای (به انگلیسی: categorical distribution) استفاده شود. توزیع رستهای، توزیع احتمالاتی بر روی نتیجه مختلف است.
تابع بیشینههموار در روشهای طبقهبندی متعددی استفاده میشود؛ مانند: رگرسیون لجستیک چندجملهای[1]:206–209 (به انگلیسی: multinomial logistic regression)، آنالیز افتراقی خطی، دستهبندی کننده بیز ساده و شبکه عصبی مصنوعی.[2] در رگرسیون لجستیک چندجملهای و آنالیز افتراقی خطی، ورودی تابع، خروجی تابع خطی است و در صورتی که بردار نمونه ورودی و بردار وزنها باشد، احتمال پیشبینی شده برای کلاس ام برابر است با:




که سطر ام بردار وزنهاست و هم برابر با مقدار ضرب داخلی بردارهای ورودی و بردار وزن است. در توصیف دیگری از عبارت بالا به جای ضرب داخلی، میتوان از عملیات ترکیب توابع استفاده کرد؛ یعنی عبارت بالا به صورت ترکیب K تابع خطی و تابع بیشینههموار تلقی گردد. به عبارت دیگر عملگری که با استفاده از بردار وزن تعریف شدهاست، بر روی ورودی اعمال شده و ورودی را به برداری در فضای انتقال میدهد.[3]




علت نامگذاری
از دو منظر میتوان علت این نامگذاری را بررسی کرد؛ معنی اصلی و معنی در یادگیری ماشین.
معنی اصلی
معنی دیدگاه اول این است که تابع تابعی با دامنه و برد است؛ ولی این تابع پیوسته نیست و به همین دلیل نمیتوان مشتق آن را تعریف کرد؛ بنابراین در بسیاری از کاربردها از تابع زیر:



استفاده میشود. تابع بیشینهٔ هموار، تقریب هموار و پیوستهای از تابع بیشینه (به انگلیسی: maximum function) ارائه میکند که مشتقپذیر است.
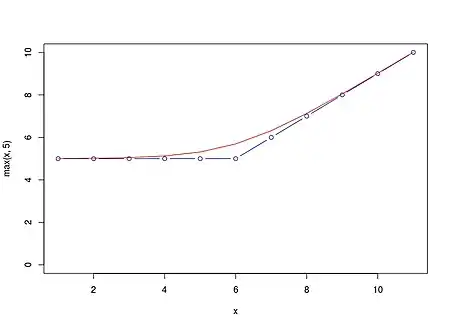
در شکل مقابل دو تابع و در بازه مقایسه شدهاند. تابع بیشینه هموار (قرمز رنگ) تقریب مشتق پذیری از تابع بیشینه (آبی رنگ) ارائه میکند.



معنی در یادگیری ماشین
در یادگیری ماشین به منظور انجام طبقهبندی (به انگلیسی: classification) از تابع بیشینهٔ هموار استفاده میشود. به طور مثال در صورتی که کلاس مختلف وجود داشته باشد و الگوریتم یادگیری ماشین به طور مستقیم احتمال حضور ورودی در هر کدام از این کلاسها را تولید نکند و به جای آن، برداری از عدد حقیقی که متناظر با امتیاز قرارگیری ورودی در هر دسته است، خروجی دهد، میتوان از تابع زیر برای تبدیل امتیازهای حقیقی به احتمال استفاده کرد؛ بدین ترتیب شرایط تعریف یک تابع جرم احتمال (قرارگیری در و جمع احتمالات برابر با ۱) رعایت خواهد شد:


که در آن تا مقادیر مطلوب احتمال و تا مقادیر حقیقی امتیازهای هر کلاس هستند.




حال پس از بررسی ضابطه تابع میتوان متوجه شد که این عبارت برابر با ضابطه تابع گرادیان بیشینهٔ هموار است.[4]


مثال
اگر ورودی باشد، مقدار تابع بیشینهٔ هموار برابر با بردارِ خواهد بود. همانطور که در قسمت قبل اشاره شد، به دلیل نمایی بودن تابع بیشینهٔ هموار، مقدار خروجی متناظر با عدد بیشینه در ورودی، از خروجی بقیه اعداد به مراتب بیشتر شدهاست.


در زیر کد این تابع با ورودی مثال، به زبان R آمدهاست:
> softmax <- function(inp) {
+ s <- sum(exp(inp))
+ return(exp(inp)/s)
+ }
>
> inp <- c(5, 2, 3, 1, 2, 3)
> softmax(inp)
[1] 0.72017036 0.03585517 0.09746446 0.01319038 0.03585517 0.09746446
شبکههای عصبی مصنوعی
میتوان از تابع بیشینهٔ هموار در لایه آخر شبکههای عصبی مصنوعی استفاده کرد[5]. چنین شبکههای عصبی معمولاً به وسیله یک تابع اختلاف آنتروپی (به انگلیسی: Cross Entropy) تعلیم داده میشوند و یک حالت غیرخطی از تابع رگرسیون لجستیک چندجملهای حاصل میشود.
به دلیل اینکه تابع، یک بردار و یک اندیس مشخص را به یک عدد حقیقی نگاشت میکند، این اندیس در مشتقات نیز ظاهر میشود:

در اینجا از تابع دلتا کرونکر استفاده شدهاست.
یادگیری تقویتی
در حوزه یادگیری تقویتی شبیه آنچه در قسمت نامگذاری گفته شد، از تابع بیشینهٔ هموار میتوان برای تبدیل مقادیر به احتمال کنش استفاده کرد.[6]
ضابطه تابعی که به طور متداول استفاده میشود برابر است با:

که در این تابع مقدار کنش متناظر است با امتیاز پیشبینی شدهٔ آن عمل و از نیز به عنوان پارامتر دما یاد میشود (با اشاره به مکانیک آماری). برای دماهای بالا () تقریباً همه کنشها احتمال یکسانی دارند و هرچه دما پایینتر باشد، مقدار پیشبینی شدهٔ تأثیر جایزه بر احتمال بیشتر است. در دمای کم () احتمال مربوط به کنشی که بیشترین امتیاز نسبت به سایر کنشها را دارد، به ۱ میل میکند.





نرمالسازی بیشینهٔ هموار
نرمالسازی بیشینهٔ هموار یا نرمالسازی سیگموید، روشی برای کاهش اثر دادههای پرت بدون حذف این دادهها از مجموعه است. وجود این دادههای پرت میتواند مفید باشد در صورتی که بتوان مقدار قابل توجهی از دادهها را در شعاع یک واحد انحراف معیار از میانگین نگه داشت.
دادهها به صورت غیرخطی به وسیله یکی از توابع سیگموید انتقال داده میشوند:
تابع سیگموید لجستیک:[7]

تابع تابع_هذلولوی، :[7]


تابع سیگموید بازه اعداد را به محدوده صفر تا یک نگاشت میکند. این تابع در محدوده میانگین تقریباً خطی است و در دو سر طیف مقادیر آن، شیب ملایمی دارد و به این ترتیب از محدود بودن برد آن و کراندار بودن آن اطمینان حاصل میشود. همچنین این خاصیت موجب میشود بیشتر مقادیر در فاصله یک واحد انحراف معیار نسبت به میانگین قرار گیرند.
تابع تانژانت هذلولوی مقادیر ورودی را به بازی -۱ تا ۱ نگاشت میکند. این تابع در نزدیک میانگین تقریباً خطی است ولی شیبی تقریباً برابر با نصف شیب تابع سیگموید دارد. مانند تابع سیگموید، این تابع در همه نقاط برد مشتق پذیر است و جهت شیب آن توسط نرمالسازی تأثیری نمیبیند. این خاصیت به الگوریتمهای عددی و الگوریتمهای بهینهسازی اطمینان میدهد که تغییر مشتق تابع پس از نرمالسازی روند مشابهی با دادههای اولیه (پیش از نرمالسازی) دارد.
ارتباط آن با توزیع بولتسمان
احتمال یافتن یک اتم در سطح انرژی کوانتومی هنگامی که این اتم جزئی از یک گروه باشد که آن گروه به تعادل دمایی در دمای رسیدهاست، برابر با مقدار تابع بیشینهٔ هموار است که از آن به عنوان توزیع بولتسمان یاد میشود. مقدار متوسط اشتغال شدن هر سطح برابر با است و این مقدار نرمالسازی شده تا جمع انرژی ۱ شود. در چنین محیطی، ورودی تابع بیشینهٔ هموار مقدارِ منفیِ انرژی هر سطح کوانتومی تقسیم بر است.




منابع
- Bishop, Christopher M. (2006). Pattern Recognition and Machine Learning. Springer.
- ai-faq What is a softmax activation function?
- Wikipedia contributors. "Multinomial Logistic Regression". Retrieved 20 August 2017.
- Charles Yang Zheng. "What does the term soft max mean in the context of machine learning". Retrieved 23 August 2017.
- Michael A. Nielsen (2015). Neural Networks and Deep Learning. Determination Press. line feed character in
|title=at position 20 (help) - Sutton, R. S. and Barto A. G. Reinforcement Learning: An Introduction. The MIT Press, Cambridge, MA, 1998.Softmax Action Selection بایگانیشده در ۲۵ ژوئن ۲۰۱۶ توسط Wayback Machine
- Artificial Neural Networks: An Introduction. 2005. pp. 16–17.