DBSCAN
DBSCAN یک روش خوشهبندی است که توسط مارتین اِستر، هانس-پتر کریگل، یورگ ساندر و شیائووی شو در ۱۹۹۶ میلادی (۱۳۷۵ شمسی) ارائه گردیدهاست.[1] مزیت این روش به نسبت روشهای دیگری خوشهبندی مانند خوشهبندی کی-میانگین این است که نسبت به شکل دادهها حساس نمیباشد و میتواند اشکال غیر منظم را نیز در دادهها تشخیص دهد.[2]
| یادگیری ماشین و دادهکاوی |
|---|
 |
الگوریتم DBSCAN
این الگوریتم نیز به مانند دیگر روشهای خوشه بندی نیازمند روشی برای یافتن نزدیکی دادهها است. میتوان از فاصله اقلیدسی جهت اندازهگیری فاصله (شباهت) استفاده نمود. برای تشریح الگوریتم، نیازمند آشنایی با پارامترهای ε و μ میباشد که توضیح داده میشود:
- هر نقطه از داده با نقاط دیگر فاصلهای دارد. هر نقطهای که فاصله اش با یک نقطه مفروض کمتر از (ε (EPS باشد به عنوان همسایه آن نقطه حساب میشود.
- هر نقطه مفروض که (μ (MinPoints همسایه داشته باشد، یک نقطه مرکزی است.
ارتباط نقاط
همچنین ارتباط نقاط بر اساس وضعیتشان (مرکزی بودن یا نبودن) در هر خوشه، به سه دسته تقسیم میشوند:
- نقاط متصل: نقطه به یک خوشه متصل است که اولاً نقطه مرکزی باشد. ثانیاً با یکی از نقاط داخل خوشه همسایه باشند.
- نقاط دسترسی پذیر: نقطه به خوشه دسترسی پذیر است که نقطه مرکزی نباشد ولی با یکی از نقاط داخل خوشه همسایه باشد.
- اگر نقطه هیچیک از وضعیتهای بالا را نداشته باشد، نویز برای آن خوشه محسوب میشود. همچنین اگر نقطه نسبت به تمام خوشهها نویز باشد، در خوشه نویز قرار میگیرد.
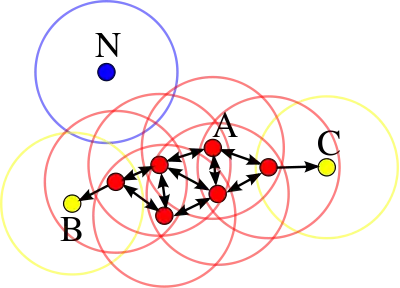
در شکل زیر نقاط قرمز رنگ نقاط مرکزی هستند. نقاط زرد به خوشه مشخص شده دسترسی دارند. نقطه آبی، نویز است. برای شکل زیر μ برابر با ۳ در نظر گرفته شدهاست.
روند الگوریتم در شبه کد زیر آورده شدهاست. در ابتدا نقطه به صورت اختیاری انتخاب میشود که قبلاً بازدید نشدهاست. همسایگی این نقطه به شعاع ε بررسی میشود و در صورتی که حداقل تعداد نقاط همسایگی لازم را داشت. خوشه ایجاد میشود وگرنه نقطه نویزی برچسب میخورد. نکته قابل این است که در ادامه ممکن است این نقطه در همسایگی دیگر نقاط قرار گیردو قسمتی از خوشه دیگر شود.
DBSCAN(D, eps, MinPts) {
C = ۰
for each point P in dataset D {
if P is visited
continue next point
mark P as visited
NeighborPts = regionQuery(P, eps)
if sizeof(NeighborPts) <MinPts
mark P as NOISE
else {
C = next cluster
expandCluster(P, NeighborPts, C, eps, MinPts)
}
}
}
expandCluster(P, NeighborPts, C, eps, MinPts) {
add P to cluster C
for each point P' in NeighborPts {
if P' is not visited {
mark P' as visited
NeighborPts' = regionQuery(P', eps)
if sizeof(NeighborPts')>= MinPts
NeighborPts = NeighborPts joined with NeighborPts'
}
if P' is not yet member of any cluster
add P' to cluster C
}
}
regionQuery(P, eps)
return all points within P's eps-neighborhood (including P)
مزایا و معایب
مزایا:
- سریع برای دادههای با بعد کم
- یافتن خوشهها برای اشکال نا منظم و کروی
- تشخیص نقاط نویز
معایب:
- نقاط مرزی که میتوانند در دو خوشه نیز باشند، ممکن است به هریک از خوشهها تعلق گیرند.
- این روش بنابه تغییرات در μ و ε رفتار غیرقابل پیش بینی میتواند داشته باشد[3]
پیادهسازی
این روش در مقاله اصلی با زبان C++ پیادهسازی شدهاست ولی اکنون پیادهسازیهای زیادی از آن وجود دارند:
منابع
- Ester, Martin; Kriegel, Hans-Peter; Sander, Jörg; Xu, Xiaowei (1996). Simoudis, Evangelos; Han, Jiawei; Fayyad, Usama M., eds. A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD-96). انجمن پیشبرد هوش مصنوعی. pp. 226–231. CiteSeerX 10.1.1.121.9220. ISBN 1-57735-004-9.
- «نسخه آرشیو شده». بایگانیشده از اصلی در ۷ مارس ۲۰۱۶. دریافتشده در ۱۰ نوامبر ۲۰۱۵.
- http://www.sciencedirect.com/science/article/pii/S0378437114000557
