جنگل تصادفی
جنگل تصادفی یا جنگلهای تصمیم تصادفی (به انگلیسی: Random forest) یک روش یادگیری ترکیبی برای دستهبندی، رگرسیون میباشد، که بر اساس ساختاری متشکل از شمار بسیاری درخت تصمیم، بر روی زمان آموزش و خروجی کلاسها (کلاسبندی) یا برای پیشبینیهای هر درخت به شکل مجزا، کار میکنند. جنگلهای تصادفی برای درختان تصمیم که در مجموعهٔ آموزشی دچار بیش برازش میشوند، مناسب هستند. عملکرد جنگل تصادفی معمولا بهتر از درخت تصمیم است، اما این بهبود عملکرد تا حدی به نوع داده هم بستگی دارد.[1][2][3]
نخستین الگوریتم برای جنگلهای تصمیم تصادفی را «تین کم هو» با بهرهگیری از روش زیرفضاهای تصادفی پدیدآورد.[4][5] نسخههای بعدی آن توسط لیو بریمن ارتقا یافت.[6]
پیشینه
پژوهشهای «بریمن» روی کار «امیت و گمن» اثر گذاشت، کسانی که پژوهش براساس دسته تصادفی که نود را تقسیم میکند (در مبحث بزرگ شدن تک درخت) ارائه کردند در این روش، پیش از این که هر درخت یا هر گره را جاسازی کنند، جنگلی از درختان بزرگ میشود و گزینش از بین گونهای از درختان که برای گزینش تصادفی زیرفضاهایی از داده آموزش دیدهاند، صورت میگیرد. در پایان ایده بهبود بخشیدن به گرههای تصادفی (که انتخاب هر گره به شکل تصادفی بوده) به جای بهبودی قطعی توسط «دیتریش» بیان شد دستاوردهای دربارهٔ جنگل تصادفی نخستین بار به دست «لئو بریمن» مقاله شد.
این مقاله روشهایی از چگونگی ساخت جنگل بدون کنترل درختها با بهرهگیری از CART را بیان میکند که با متد بگینگ و بهبودی نود تصادفی ترکیب شدهاست. به علاوه، این مقاله بسیاری از نتایج اولیه به دست آمده که شناخته شده بودند و چه آنهایی که به چاپ رسیده بودند را ترکیب میکرد که این ترکیبات پایه و اساس تمرینات امروزی جنگلهای تصادفی را شامل میشود این الگوریتم توسط «لئو بریمن و عادل کالچر» توسعه یافت که جنگل تصادفی نیز جزو دستاوردهای ایشان بود ایده بگینگ برای ساخت مجموعهای از درختهای تصمیم و انتخاب تصادفی نخست توسط «هو» و سپس «امیت و گمان» کامل شد. این تمرینات امروزی عبارتند از:
۱. بهره گرفتن از نقص خارج از کیسه برای تعمیم نقصهای سازماندهی
۲. اهمیت اندازهگیری گونهها و تنوع از طریق جایگشت
همچنین این گزارش نخستین فرجام تئوری برای جنگلهایی که از راه نقص سازماندهی تعمیم یافته بودند را بیان میکند که بستگی به قدرت درختها و ارتباط آنها دارد.
الگوریتم
آغاز: آموزش درخت تصمیم
درخت تصمیم روش مشهوری برای انواع مختلفی از وظایف یادگیری ماشین به حساب می آید. با این حال در بسیاری موارد دقیق نیستند.[1][3]
در کل، معمولا درخت تصمیمی که بیش از حد عمیق باشد الگوی دقیق نخواهد داشت: دچار بیش برارزش شده , و دارای سوگیری پایین و واریانس بالا میباشد. جنگل تصادفی روشی است برای میانگین گیری با هدف کاهش واریانس با استفاده از درخت های تصمیم عمیقی که از قسمت های مختلف داده آموزشی ایجاد شده باشند. در این روش معمولا افزایش جزیی سوگیری و از دست رفتن کمی از قابلیت تفسیر اتفاق افتاده اما در کل عملکرد مدل را بسیار افزایش خواهد داد.[1][2]
کیسهگذاری درختان
مجموعه داده را با نمایش میدهیم، و درخت تصادفی با ایجاد داده جدید از ایجاد میکنیم. مدل نهایی با میانگین گرفتن یا رأیگیری بین درختان کار میکند[7]. جزئیات این الگوریتم ذیلاً آمده است:



برای تا :

- نمونه با جایگزینی از داده انتخاب کن و این نمونهها را در مجموعه داده قرار بده. از آنجا که نمونهگیری با جایگزینی صورت میگیرد یک نمونه ممکن است چندین بار انتخاب شود.
- یک درخت تصادفی به اسم با به روش پایین بساز:
- هر دفعه برای پیدا کردن بهترین متغیر ابتدا یک تعداد مشخصی از متغیرها را کاملا به صورت تصادفی انتخاب کن (مثلا تا، از قبل به مسئله داده شدهاست، و معمولاً با جذر تعداد متغیرها برابر است) و از میان آنها بهترین متغیر را انتخاب کن.




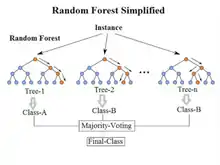
در مسئله رگرسیون مدل نهائی، میانگین تمامی درختها است[7] یعنی . از طرفی دیگر در مسئله دستهبندی یا Classification با رأیگیری بین درختان به جواب نهائی میرسیم[7].

این نوع ترکیب مدلها جواب بهتری به ما میدهد زیرا گوناگونی و تنوع مدلها را افزایش میدهد بدون این که بایاس را افزایش دهد! این بدین معناست که زمانی که پیشبینی تکی از یک درخت دارای نویز بالایی درون مجموعه دسته آموزش دیده اش باشد، در میانگین بسیاری از درختها این نویز وجود نخواهد داشت. به شکل ساده آموزش درختان به صورت تکی میتواند درختهای در ارتباط قوی تری را ارائه دهد. بوت استرپ کردن نمونه، روشی برای یکپارچهتر کردن درختها با نمایش مجموعه دادههای آموزش دیده گوناگون است.
از کیسهگذاری تا جنگل تصادفی
روندی که گفته شد الگوریتم اصلی بگینگ برای درختان را توصیف میکند. جنگل تصادفی تنها یک اختلاف با این طرح کلی دارد: و آن این که از یک الگوریتم یادگیری درخت اصلاح شدهاستفاده میکند که در هر تقسیم کاندیدها در فرایند یادگیری، زیر مجموعهای تصادفی از ویژگیهای آن را پردازش میکنند. این پردازش گاهی «کیسهگذاری ویژگی» نامیده میشود. دلیل انجام این کار این است که ارتباط درختها در یک نمونه بوت استرپ معمولی را نشان میدهد. اگر یک یا چند ویژگی پیشبینیکنندهها، برای متغیر پاسخ (خروجی هدف) بسیار قوی باشد، این ویژگی در بسیاری از درختهای B که سبب ارتباط آنها میشود، انتخاب خواهد شد. آنالیز چگونگی کارکرد بگینگ و مجموعه دستههای تصادفی، کمک میکند تا بتوان به دقتهای با شرایط گوناگون دست یافت که توسط «هو» نیز ارائه شده بودند.
درختان افزونه
برای آشنایی با بخشی از سازوکار این درختها باید دانست که، جنگل تصادفی پیشبینیکننده به صورت طبیعی اندازهگیریهای بدون برچسب را از بین درختان بدون نظارت رهبری میکند. این درخت میتواند همچنین جنگل تصادفی را بین دادههای بدون برچسب تعریف کند: به این شکل که ساخت جنگل تصادفی پیشبینیکننده دادههای مشاهده شده را از دادههای مصنوعی مناسب متمایز میکند. دادههای مشاهده شده، دادههای اصلی بدون برچسب هستند و دادههای مصنوعی از مرجع توزیعها گرفته میشود. یک جنگل تصادفی میتواند جالب به نظر برسد زیرا میتواند دادههای ترکیبی را به خوبی مدیرت کند، و از لحاظ مشاهدات قوی است. جنگل تصادفی میتواند به سادگی به متمایز کردن شمار زیادی از متغیرهای ناپیوسته از متغیر ذاتی بپردازد. برای مثال، Addcl 1 در جنگل تصادفی بدون تشابه وزنها سهم هر متغیر، به چگونگی وابستگی آن به دیگر متغیرها بستگی دارد. جنگل تصادفی بدون تشابه در بسیاری از اپلیکیشنها به کار رفتهاست مانند پیدا کردن خوشهای از بیماران برپایهٔ دادههای نشانگر بافت.
ویژگان
اهمیت متغیرها
جنگل تصادفی میتواند برای رتبهبندی اهمیت متغیرها در یک رگرسیون یا مساله طبقهبندی به کار رود. تکنیکی که در ادامه آمدهاست در مقاله اصلی «بریمن» آورده شده بود و در پکیج کردن R جنگل تصادفی اجرا میشود. نخستین گام در اهمیت اندازهگیری متغیرها در مجموعه دادهها، Dn={(xi,yi)} جای دادن جنگل تصادفی در داده هاست. در هنگام انجام این فرایند جایگذاری نقص بیرون از کیسه برای هر داده ضبط میشود و به عنوان میانگینی از میان جنگل محسوب میگردد. برای اندازهگیری اهمیت j امین ویژگی بعد از آموزش، مقدار jامین ویژگی permuted از میان دادههای آموزش دیده و نقص خارج از کیسه دوباره روی این مجموعه داده محاسبه خواهد شد. اهمیت نمره برای j امین ویژگی از روش میانگینگیری از تفاوتها در خارج از کیسه قبل و بعد از permutation روی تمام درختها به دست میآید. این نمره با استانداردسازی انحرافات متفاوت، نرمالسازی میشود. ویژگیهایی که مقادیر بسیاری برای این نمره تولید میکنند بسیار با اهمیت تر هستند نسبت به آن ویژگیهایی که مقدار کوچکی تولید میکنند.[2]
این روش تعیین متغیر با اهمیت، شامل برخی اشکالات میشود. برای دادهای که شامل متغیرهای بخشبندی شده با سطوح مختلف از شماره هاست، جنگل تصادفی به این خاصیتشان اهمیت میدهد که دارای چندین سطح هستند. متدهایی همانند partial permutations و درختان در حال رشد بیطرف، میتواند برای حل مشکل به کار گرفته شوند. اگر داده شامل گروههایی از ویژگیهای مرتبط به هم با شبیهسازی برای خروجی باشد، در این حالت گروههای کوچک نسبت به گروههای بزرگ برتری دارند.
رابطه با الگوریتم نزدیکترین همسایهها
ارتباط بین جنگل تصادفی و الگوریتم کی-نزدیکترین همسایه (K-NN) در سال ۲۰۰۲ توسط «لین» و «جو» استخراج شد. به نظر میرسد که هردوی آنها میتوانند به عنوان طرح پروزنترین همسایه نامگذاری شوند.
اینها مدلهایی برای ساخت دادههای آموزش دیده {(xi,yi)} هستند که پیشبینیهای تازه y را برای x' با نگاه به همسایگی از نقاط، از طریق تابع وزن به صورت زیر در میآورد:
y=Π w(xi,x') yi
در اینجا W(xi,x') وزن غیر منفی از i امین نقطه آموزش دیدهٔ همسایه با نقطه تازه x' است. برای هر 'x ویژه، ورن باید جمعی با یک باشد. تابعهای وزن در زیر آورده شدهاند:
۱. در k-NN وزنها W(xi,x') = 1/K هستند، اگر xi یکی از نقاطk که نزدیکترین به x' است، در نظر گرفته شود، و درغیر این صورت صفر باشد.
۲. در درخت w(xi,x')=1/k' اگر xi یکی از نقاط k' در برگ یکسان از x' باشد، و در غیر این صورت صفر باشد.
به سبب این که میانگین جنگل مجموعهای از درختهای m را با تابع وزن فردی wj پیشبینی میکند، پیشبینیهایش به صورت زیر در میآید:
y= 1/m ΠΠ wj(xi,x')yi=Π(1/mΠ wj(xi,x'))yi
این نشان میدهد که کل جنگل یک طرح از دوباره وزنگیری همسایه هاست، با وزنهایی که میانگین هر درخت مجزا هستند. همسایههای x' در این تفسیر ویژگی، نقاط xiهایی هستند که در یک برگ یکسان از x'ها در دست کم یک درخت از جنگل قرار دارند. در این روش، همسایگی x' به پیچیدگی یک ساختار از درخت بستگی دارد، و همچنین به ساختار یک مجموعه آموزش دیده. «لین» و «جو» نشان دادند که شکل همسایگی ای که جنگل تصادفی از آن بهره گرفتهاست مطابق است با اهمیت محلی از هر ویژگی.
یادگیری بینظارت با جنگل تصادفی
به عنوان بخشی از سازوکار آنها، جنگل تصادفی پیشبینیکننده به صورت طبیعی اندازهگیریهای بدون برچسب را میان بدون نظارتها رهبری میکند. میتواند همچنین جنگل تصادفی را بین دادههای بدون برچسب تعریف کند: ایده این است که ساخت جنگل تصادفی پیشبینیکننده دادههای مشاهده شده را از دادههای مصنوعی مناسب متمایز میکند. دادههای مشاهده شده، دادههای اصلی بدون برچسب هستند و دادههای مصنوعی از مرجع توزیعها گرفته میشود. یک جنگل تصادفی میتواند جالب به نظر برسد زیرا میتواند دادههای ترکیبی را به خوبی مدیرت کند، و از لحاظ مشاهدات قوی است. جنگل تصادفی میتواند به سادگی به متمایز کردن شمار زیادی از متغیرهای ناپیوسته از متغیر ذاتی بپردازد. برای مثال، Addcl 1 جنگل تصادفی بدون تشابه وزنها سهم هر متغیر وابسته به چگونگی وابستگی آن به دیگر متغیرها بستگی دارد. جنگل تصادفی بدون تشابه در بسیاری از اپلیکیشنها بکار رفتهاست مانند پیدا کردن خوشهای از بیماران برپایهٔ دادههای نشانگر بافت.
انواع
در میان ابزارهای پشتیبانی تصمیم، درخت تصمیم و دیاگرام تصمیم دارای مزایایی هستند:
۱- فهم ساده: هر انسان با اندکی مطالعه و آموزش میتواند، طریقه کار با درخت تصمیم را بیاموزد.
۲- کار کردن با دادههای بزرگ و پیچیده: درخت تصمیم در عین سادگی میتواند با دادههای پیچیده به راحتی کار کند و از روی آنها تصمیم بسازد.
۳-استفاده مجدد آسان: در صورتی که درخت تصمیم برای یک مسئله ساخته شد، نمونههای مختلف از آن مسئله را میتوان با آن درخت تصمیم محاسبه کرد.
۴- قابلیت ترکیب با روشهای دیگر: نتیجه درخت تصمیم را میتوان با تکنیکهای تصمیمسازی دیگر ترکیب کرده و نتایج بهتری بدست آورد.
مثال ۱
درخت تصمیم در بهینهسازی مشارکت اوراق بهادار مورد استفاده قرار گیرد. مثال زیر اوراق بهدار ۷ طرح مختلف را نشان میدهد. شرکت ۱۰۰۰۰۰۰۰۰ برای کل سرمایهگذاریها دارد. خطوط پر رنگ نشان دهنده بهترین انتخاب است که موارد ۱، ۳، ۵، ۶ و۷ را در بر میگیرد و هزینهای برابر ۹۷۵۰۰۰۰ دارد و سودی برابر ۱۶۱۷۵۰۰۰ برای شرکت فراهم میکند. مابقی حالات یا سود کمتری دارد یا هزینه بیشتری میطلبد.[8]
مثال ۲
در بازی بیست سؤالی، بازیکن باید یک درخت تصمیم در ذهن خود بسازد که به خوبی موارد را از هم جدا کند تا با کمترین سؤال به جواب برسد. در صورتی بازیکن به جواب میرسد که درخت ساخته شده بتواند به خوبی موارد را از هم جدا کند.
جستارهای وابسته
- تقویت گرادیان
- جدول تصمیم
- پیچیدگی درخت تصمیم
- آنالیز تصمیم
- درخت
- گراف تصمیم
- شبکه تصمیم
- زنجیره مارکف
- دیاگرام تصمیم
منابع
- Piryonesi, S. M.; El-Diraby, T. E. (2020) [Published online: December 21, 2019]. "Data Analytics in Asset Management: Cost-Effective Prediction of the Pavement Condition Index". Journal of Infrastructure Systems. 26 (1). doi:10.1061/(ASCE)IS.1943-555X.0000512.
- Piryonesi, S. Madeh; El-Diraby, Tamer E. (2020-06). "Role of Data Analytics in Infrastructure Asset Management: Overcoming Data Size and Quality Problems". Journal of Transportation Engineering, Part B: Pavements. 146 (2): 04020022. doi:10.1061/jpeodx.0000175. ISSN 2573-5438. Check date values in:
|date=(help) - Hastie, Trevor. (2001). The elements of statistical learning : data mining, inference, and prediction : with 200 full-color illustrations. Tibshirani, Robert., Friedman, J. H. (Jerome H.). New York: Springer. ISBN 0-387-95284-5. OCLC 46809224.
- Ho, Tin Kam (1995). Random Decision Forests (PDF). Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, 14–16 August 1995. pp. 278–282. Archived from the original (PDF) on 17 April 2016. Retrieved 5 June 2016.
- Ho TK (1998). "The Random Subspace Method for Constructing Decision Forests" (PDF). IEEE Transactions on Pattern Analysis and Machine Intelligence. 20 (8): 832–844. doi:10.1109/34.709601. Archived from the original (PDF) on 4 March 2016. Retrieved 29 April 2019.
- Breiman L (2001). "Random Forests". Machine Learning. 45 (1): 5–32. doi:10.1023/A:1010933404324.
- Breiman, Leo (2001). "Random Forests". Machine Learning (به English). 45 (1): 5–32. doi:10.1023/a:1010933404324. ISSN 0885-6125.
- Y. Yuan and M.J. Shaw, Induction of fuzzy decision trees بایگانیشده در ۱۰ فوریه ۲۰۰۹ توسط Wayback Machine. Fuzzy Sets and Systems ۶۹ (۱۹۹۵), pp. 125–139
منابع
- Sequential decision making with partially ordered preferences Daniel Kikuti, Fabio Gagliardi Cozman , Ricardo Shirota Filho
پیوند به بیرون
| در ویکیانبار پروندههایی دربارهٔ جنگل تصادفی موجود است. |
- Decision Tree Web Application
- 5 Myths About Decision Tree Analysis in Litigation
- Decision Tree Analysis mindtools.com
- Decision Analysis open course at George Mason University
- Extensive Decision Tree tutorials and examples
- Cha, Sung-Hyuk (2009). "A Genetic Algorithm for Constructing Compact Binary Decision Trees". Journal of Pattern Recognition Research. 4 (1): ۱–۱۳. Unknown parameter
|coauthors=ignored (|author=suggested) (help); External link in|journal=(help) - Decision Trees in PMML
