خودرمزگذار
خودرمزگذار (به انگلیسی: autoencoder) یک شبکه عصبی مصنوعی است که برای کدینگ از آن استفاده میشود.[1] از خود رمزگذارها برای استخراج ویژگی و فشرده سازی نمایش دادههای با ابعاد بالا، یا به عبارت دیگر برای کاهش ابعاد استفاده میشود.
در یک خودرمزگذار میتوان ۳ یا تعداد بیشتری لایه داشت:
- لایه ورودی
- لایه (ها) ی پنهان
- لایه خروجی
در ساده ترین حالت یک خودرمزگذار شامل یک encoder (رمزگذار) و decoder (رمزگشا) به همراه تنها یک لایه پنهان میباشد. ورودی به encoder داده شده و خروجی از decoder استخراج میشود. در این نوع شبکه به جای آموزش شبکه و پیشبینی مقدار تابع هدف در ازای ورودی X ، خودرمزگذار آموزش میبیند که ورودی خود را بازسازی کند؛ بنابراین بردار خروجی همان ابعاد بردار ورودی X را خواهد داشت؛ یعنی تعداد نورونهای موجود در لایه ورودی و خروجی با یکدیگر برابر است. همانطور که گفته شد در این شبکه خروجی بازسازی ورودی بوده و از الگوریتم پس انتشار[1] خطا برای یادگیری استفاده میشود. خودرمزگذارها با حداقل کردن خطای بازسازی[2] شبکه را آموزش میدهند. معمولا تعداد نورونهای موجود در لایه پنهان کمتر از لایه encoder/decoder میباشد. لایه پنهان یا کد در حقیقت representation یا نمایش داده در فضای بعد کاهش یافته آن میباشد و عملا متناظر با ویژگی های استخراج شده است. پس از آموزش شبکه بخش decoder حذف شده و خروجی میانیترین لایه پنهان[3] به عنوان ویژگی های استخراج شده در نظر گرفته میشود. به منظور کاهش بیشتر ابعاد میبایست از تعداد لایه های پنهان بیشتری در شبکه استفاده کرد که در اصطلاح خودرمزگذار عمیق نامیده میشود.
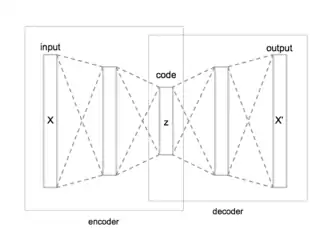
[1] BackPropagation
[2] Reconstruction
[3] Innermost Hidden Layer
در صورتی که در لایه میانی تنها از توابع خطی استفاده شود یا اینکه تنها از یک لایه سیگموید استفاده شود، عملکرد شبکه مطابق با تحلیل مؤلفههای اصلی است.[2]
آموزش
یک شبکه عصبی خودرمزگذار با تنظیم مقادیر خروجی هدف برابر با مقادیر ورودی، پسانتشار را انجام میدهد و بدین ترتیب خودرمزنگار آموزش داده میشود تا اختلاف بین دادهها و بازسازی آن را به حداقل برساند (یعنی تفاوت بین بردار واقعی خروجی و بردار خروجی مورد انتظار، که در آن خروجی مورد انتظار همان بردار ورودی است). در نتیجه، خودرمزنگارها قادر به یادگیری بدون معلم (ناظر) هستند.[3]
منابع
- Modeling word perception using the Elman network, Liou, C. -Y. , Huang, J. -C. and Yang, W. -C. Neurocomputing, Volume 71, 3150–3157 (2008), doi:10.1016/j.neucom.2008.04.030
- Auto-association by multilayer perceptrons and singular value decomposition, H. Bourlard and Y. Kamp Biological, Cybernetics Volume 59, Numbers 4-5, 291-294, doi:10.1007/BF00332918
- میلاد وزان، یادگیری عمیق: اصول، مفاهیم و رویکردها، میعاد اندیشه، 1399
جستارهای وابسته
- ماشین بولتزمن محدود شده
