کدگذاری هافمن
در علوم کامپیوتر و تئوری اطلاعات، کدگذاری هافمن (به انگلیسی: Huffman coding) نوع مشخصی از کد پیشوندی (به انگلیسی: Prefix code) بهینه است که کاربردی فراوان در فشردهسازی بیاتلاف اطلاعات دارد. فرایند پیدا کردن یا استفاده از این کد، با بهرهگیری از الگوریتمی انجام میشود که توسط «دیوید هافمن» (زمانی که وی دانشجوی دوره دکتری در دانشگاه MIT بود) توسعه داده شدهاست و برای اولین بار در سال 1952 در مقالهای با عنوان «روشی برای تولید کدی با کمترین تکرار زوائد»[1] منتشر شد.
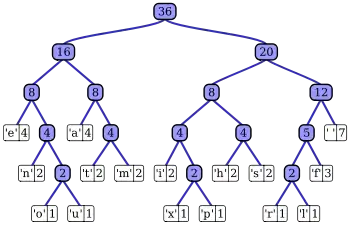
| کد | تکرار | حرف |
|---|---|---|
| 111 | 7 | space |
| 010 | 4 | a |
| 000 | 4 | e |
| 1101 | 3 | f |
| 1010 | 2 | h |
| 1000 | 2 | i |
| 0111 | 2 | m |
| 0010 | 2 | n |
| 1011 | 2 | s |
| 0110 | 2 | t |
| 11001 | 1 | l |
| 00110 | 1 | o |
| 10011 | 1 | p |
| 11000 | 1 | r |
| 00111 | 1 | u |
| 10010 | 1 | x |
میتوان به خروجی الگوریتم هافمن به عنوان یک جدول کد طول متغیر نگاه کرد که با استفاده تخمین احتمال حضور و یا فراوانی تکرار حروف در فایل منبع ایجاد شدهاست و مانند هر رمزگذاری درگاشتی دیگر، حروف پرتکرار تر با تعداد بیتهای کمتری نمایش داده میشوند.
باید دقت کرد با توجه به کارآیی بالای این الگوریتم، کدگذاری هافمن همواره بهینه نیست و در مواری که قصد فشردهسازی بهینهتری داشته باشیم، میتوان از الگوریتمهای کدگذاری حسابی و یا سیستمهای عددی نامتقارن استفاده کرد.
تاریخچه
در سال 1951 میلادی، دیوید هافمن و هم شاگردیهایش در کلاس تئوری اطلاعات در دانشگاه MIT، حق انتخاب بین تحقیق در مورد یک مفهوم یا شرکت در امتحان پایانی را داشتند. دکتر روبرتو فانو موضوع تحقیق را یافتن کارآمدترین کد دودویی تعیین کرد. هافمن که در ابتدا موفق به یافتن کارآمدترین کد نشده بود،تصمیم گرفت خودش را برای شرکت در امتحان پایانی آماده کند. که ایدهی استفاده از درخت دودیی مرتب شده برحسب فراوانی به ذهنش رسید. او در نهایت توانست اثبات کند که روش کارآمدترین روش است.[2] در انجام این کار، شاگرد از استادش که با مبدع تئوری اطلاعات، کلود شانون برای ساختن کدی مشابه کار کرده بود، پیشی گرفت. هافمن از مشکل اصلی روش کدگذاری نیم بهینهٔ رمزگذاری شانون-فانو جلوگیری کرد و درخت را به جای ساختن از بالا به پایین، از پایین به بالا ساخت.
واژهشناسی
در کدگذاری هافمن، از روشی به نام کدهای بدون پیشوند (که به عنوان «کدهای پیشوندی» نیز شناخته میشود) برای انتخاب نحوهٔ نمایش هر نماد استفاده میشود. در این روش نویسههای پرکاربردتر با رشتههای بیتی کوتاهتری نسبت به آنهایی که کاربردشان کمتر است، نشان داده میشوند. کدگذاری هفمن به اندازهای پرکابرد است که کلمه «کد هافمن» به صورت گسترده به عنوان مترادفی برای کدهای پیشوندی استفاده میشود.
تعریف مسئله
تعریف غیر رسمی
دادههای مسئله:
مجموعهای از نمادها (حروف و کاراکترها) به همراه وزن هر کدام. وزن هر حرف غالبا همان تعداد تکرار آن در فایل منبع است.
خواسته:
یافتن کد دودویی بدون پیشوند با کمترین امید ریاضی برای طول کد.
تعریف رسمی
ورودی:
مجموعه حروف به طول


مجموعه وزنها که نشاندهنده وزن هر نماد (حرف) از مجموعه حروف است به طوری که:


خروجی:
مجموعه کد(دودویی) که هر عضو آن نشاندهنده کد متناسب با یکی از حروف در مجموعه است.


هدف:
با تعریف شرط بهینه بودن: برای هر کدگذاری



الگوریتم هافمن
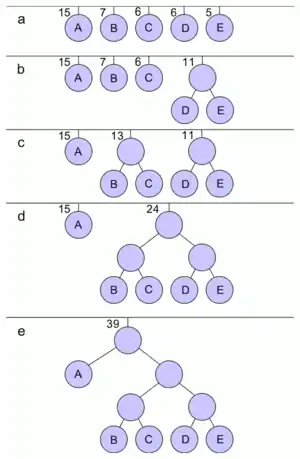
اساس الگوریتم هافمن به این صورت است که دو عضو و که دو عضو از بین حرفهایی هستند که کمترین تکرار را بین حروف مجموعه دارند، انتخاب میکنیم. حال مجموعه حروف جدید را در نظر میگیریم که شامل تمام اعضای مجموعه به جز دو عضو و است و جدید را داراست. در این مجموعه حروف جدید، وزن همهی اعضا برابر با وزن قبلی آنها در مجموعه است و وزن عضو برابر با خواهد بود. حال دوباره این الگوریتم را برای مجموعه جدید تکرار میکنیم.





مراحل الگوریتم
- اگر اندازه مجموعه حروف برابر 2 باشد، درخت بهینه از اتصال دو راس با ریشه به دست میآید.
- اگر اندازه مجموعه بیشتر از 2 باشد:
- توسط الگوریتم داده شده در بالا، و را به دست آورده و به صورت بازگشتی درخت را میسازیم.
- در درخت گرهی را با درختی سه راسی که با یک پدر و دو فرزند که هرکدام از فرزندها یکی از رئوس یا است، جایگزین میکنیم.


اثبات بهینه بودن درخت کد حاصل از الگوریتم هافمن را میتوانید در «درسنامه جلسه 10 کلاس تحلیل الگوریتمها دانشکده ریاضی دانشگاه صنعتی شریف» [3]مطالعه کنید.
پیچیدگی الگوریتم
الگوریتم هافمن اگر به صورت ساده گفته شده در بالا پیادهسازی شود، میتوان به راحتی با استفاده از رابطه بازگشتی نشان داد دارای پیچیدگی زمانی است. اما میتوان با استفاده از داده ساختار هرم الگوریتم را بهبود بخشید و پیچیدگی زمانی را به کاهش داد. در پیادهسازی این الگوریتم به سه آرایه نیاز داریم و برای هر گره در درخت، مقادیر فرزند راست ، فرزند چپ و والد را در آنها ذخیره میکنیم.







شبه کد
function BuildHuffman(W)
for i = 1 to n do
L[i] <- 0; R[i] <- 0
InsertHeap(i, W[i])
for i = n to 2n - 1 do
x <- PopMinHeap()
y <- PopMinHeap()
W[i] <- W[x] + W[y]
L[i] <- x; R[i] <- y
P[x] <- i; P[y] <- i
InsertHeap(i, W[i])
P[2n - 1] <- 0مثال
در این قسمت مثالی از کدگذاری هافمن را با مجموعهای پنج حرفی و با وزنهای داده شده (احتمال حضور) را بررسی میکنیم. در این مثال اثبات نمیکنیم مقدار برای همه کدگذاریها کمینه است بلکه مقادیر به دست آمده را با آنتروپی شانون مقایسه کرده و نشان میدهیم مقادیر به دست آمده تقریبا بهینه هستند.


| ورودی و | نماد | a | b | c | d | e | مجموع |
|---|---|---|---|---|---|---|---|
| وزن | 0.10 | 0.15 | 0.30 | 0.16 | 0.29 | = 1 | |
| خروجی | کد کلمه | 010 |
011 |
11 |
00 |
10 |
|
| طول کد (تعداد بیت) |
3 | 3 | 2 | 2 | 2 | ||
| مشارکت در طول مسیر وزن دار | 0.30 | 0.45 | 0.60 | 0.32 | 0.58 | L(C) = 2.25 | |
| بهینگی | مشارکت در آنتروپی | 0.332 | 0.411 | 0.521 | 0.423 | 0.518 | H(A) = 2.205 |

برای اطلاع از نحوه محاسبه به ویکیپدیای انگلیسی همین صفحه مراجعه کنید.
انواع
انواع مختلفی از کد گذاری هافمن وجود دارد، که بعضی از آنها از الگوریتمهایی شبیه الگوریتم هافمن و بعضی دیگر از کدهای بهینهٔ پیشوندی (با محدودیتهای خاص برای خروجی)استفاه میکنند.
در حالت اخیر، نیاز نیست که روش، شبیه روش هافمن باشد و حتی ممکن است زمان اجرایی چندجملهای هم نداشته باشد. لیست کاملی از مقالات مربوط به انواع مختلف کد گذاری هافمن، در «درختهای کد و تجزیه برای کد کردن بی زیان اطلاعات» داده شدهاست.
کد هافمن n تایی
الگوریتم کد هافمن n تایی از الفبای {۰، ۱،... ، n − ۱} برای کد کردن پیامها و ساختن درخت n تایی استفاده میکند. این روش دسترسی بوسیلهٔ هافمن و در مقاله اش بررسی شده بود.
کد هافمن انطباقی
نوع دیگری به نام کد هافمن انطباقی، احتمالاتی را که به صورت پویا و بر اساس تکرار واقعی در منبع اصلی است، محاسبه میکند. این به گونهای مربوط به خانوادهٔ الگوریتمهای LZ است.
الگوریتم الگوی هافمن
بیشتر اوقات، وزنهای مورد استفاده در اجرای کد هافمن، نمایانگر احتمالات عددی است ولی این الگوریتم چنین چیزی را نیاز ندارد بلکه فقط به راهی برای منظم کردن وزنها و اضافه کردن آنها نیازمند است. الگوریتم الگو هافمن امکان استفاده از هر نوع وزنی را میدهد.(ارزش-تکرار-جفت وزن ها-وزنهای غیر عددی) و هر کدام از روشهای ترکیبی مختلف. اینگونه الگوریتمها میتوانند مسائل فشرده سازی دیگر را نیز حل کنند.
کد هافمن با طول محدود
کد هافمن با طول محدود نوعی دیگر از کد هافمن است. این نوع هنگامی مورد استفاده قرار میگیرد که هدف هنوز بدست آوردن طول مسیر با کمترین وزن است اما یک شرط دیگر نیز وجود دارد و آن این است که اندازهٔ هر کد، باید کمتر از مقدار ثابت خاصی باشد.
الگوریتم بسته بندی-ادغام این مشکل را بهوسیلهٔ یک الگوریتم حریصانه ساده شبیه به همانی که در الگوریتم هافمن بکار رفته بود، حل میکند. پیچیدگی زمانی این الگوریتم ، که ماکزیمم طول یک کدکلمه (codeword)است.

هیچ الگوریتمی شناخته نشده که این کا را در زمان linear or linearithmic انجام دهد، بر خلاف مسائل پیش مرتب شده و مرتب نشدهٔ هافمن.
کد هافمن با ارزش حرفی متفاوت
در کد گذاری استاندارد هافمن، فرض شدهاست که هر نماد در مجموعهای که کدها از آن استخراج میشوند، ارزشی یکسان با بقیه دارد: کد کلمهای که طول آن N است ارزشی برابر N خواهد داشت، مهم نیست که چند رقم آن ۱ و چند رقم آن ۰ است. وقتی با این فرض کار میکنیم، کم کردن هزینهٔ کلی پیام، با کم کردن تعداد رقمهای کل ۲ چیز یکسانند. کد هافمن با ارزش حرفی متفاوت به نحوی عمومیت یافته که این فرض دیگر صحیح نیست: حروف الفبای کدگذاری ممکن است طولهای غیر همسانی داشته باشند، به خاطر خصوصیتهای واسطهٔ انتقال. مثالی بر این ادعا، الفبای کد گذاری کد مورس است، که در آن فرستادن یک 'خط تیره' بیشتر از فرستادن یک 'نقطه' طول میکشد، پس ارزش خط تیره در زمان انتقال بالاتر است. درست است که هدف هنوز کم کردن میانگین طول وزنی کد است اما دیگر کم کردن تعداد نمادهای بکار برده شده در پیام، به تنهایی کافی نیست. هیچ الگوریتمی شناخته نشدهاست که این را به همان روش و همان کارآیی کد قراردادی هافمن انجام دهد.
کد قانونی هافمن
اگر وزنهای مربوط به ورودیهای مرتب شده بر اساس الفبا، به ترتیب عددی باشند، کد هافمن طولی برابر طول کد الفبایی بهینه دارد که میتواند از طریق محاسبه بدست آید. کد بدست آمده از ورودیهای مرتب شده از نظر عددی، کد قانونی هافمن گفته میشود و کدی است که به خاطر سادگی رمز کردن و رمز گشایی، در عمل استفاده میشود. تکنیک پیدا کردن این کد، اکثراً کد گذاری Huffman-Shannon-Fano نامیده میشود. و این به خاطر آن است که مانند کدگذاری هافمن بهینه، ولی در احتمال وزنها مانند کد گذاری رمزگذاری شانون-فانو الفبایی است. کد هافمن Shannon-Fano مربوط به این مثال است که در آن طول کد کلمهها، همان مقداری است که در حل اصلی آمدهاست.

فهرست منابع
- Huffman, D. (1952). "A Method for the Construction of Minimum-Redundancy Codes" (PDF). Proceedings of the IRE. 40 (9): 1098–1101. doi:10.1109/JRPROC.1952.273898.
- Huffman, Ken (1991). "Profile: David A. Huffman: Encoding the "Neatness" of Ones and Zeroes". Scientific American: 54–58.
- http://sharif.ir/~shahram.khazaei/files/courses/algorithms/lecture10.pdf
جستارهای وابسته
- کد اصلاحشدهٔ هافمن به کار رفته درماشینهای فکس
- فشردهسازی دادهها
- لمپل-زیو-ولچ
- سیستمهای دودویی نامتقارن
پیوند به بیرون
| در ویکیانبار پروندههایی دربارهٔ کدگذاری هافمن موجود است. |
- Program for explaining the Huffman Coding procedure.
- Huffman Code Applet
- n-ary Huffman Template Algorithm
- Sloane A۰۹۸۹۵۰ Minimizing k-ordered sequences of maximum height Huffman tree
- Computing Huffman codes on a Turing Machine
- Mordecai J. Golin, Claire Kenyon, Neal E. Young «Huffman coding with unequal letter costs» (PDF), STOC ۲۰۰۲: ۷۸۵-۷۹۱
- Huffman Coding: A CS2 Assignment a good introduction to Huffman coding
- A quick tutorial on generating a Huffman tree
- Pointers to Huffman coding visualizations
- Huffman in C
- Huffman in Java
- Huffman binary algorithm applet
- Implementation approaches to Huffman Decoding