مسیریابی (الگوریتم)
مسیر یابی یک الگوریتم برای برنامههای کامپیوتری است که هدف آن یافتن (غالبا) کوتاهترین مسیر بین دو نقطه است. مسیر یابی یک راه کاربردی برای حل هزارتوها است.
| پیمایش گراف و پیمایش درخت |
|---|
|
هرس آلفا بتا |
| جستار وابسته |
|
برنامهریزی پویا |
مسیر یابی به مقدار زیادی به مسئلهٔ کوتاهترین مسیر در نظریهٔ گرافها ارتباط دارد؛ که در واقع این مسئله به این موضوع میپردازد که چگونه سریعترین، ارزانترین (از لحاظ تعداد راسها) و کوتاهترین مسیر را بین دو نقطه در یک شبکهٔ بزرگ بیابیم.[1]
تاریخچه
ردیابی تاریخچه مسئله مسیریابی و کوتاهترین مسیر دشوار است. میتوان تصور کرد که حتی در جوامع بسیار بدوی (حتی حیوانات) نیز این کار بسیار ضروری بودهاست (به عنوان مثال برای یافتن غذا). تحقیقات ریاضی دربارهٔ این مسئله نسبت به مسئلههای معروف دیگر دیر شروع شد. از اولین الگوریتمهایی که برای این مسئله ارائه شد میتوان به الگوریتم جستجوی اول سطح اشاره کرد.[2]
با توجه به پیشرفت کامپیوترها و ظهور مسائل جدید، این مسئله به تدریج از اواسط قرن بیستم مورد توجه قرار گرفت و با ایجاد شبکهٔ جهانی اینترنت، بیش از پیش به آن پرداخته شد. بازیهای کامپیوتری و نقشههای آنلاین، امروزه از پیشرفتهترین الگوریتمهای مسیریابی استفاده میکنند.
تعریف مسئله
مسیریابی عبارت است از پیدا کردن یک مسیر بین دو نقطه از فضا که ممکن است مابین آنها موانعی وجود داشته باشد. مسئلهٔ مسیریابی به دو زیرمسالهٔ زیر قابل تقسیم است:[3]
- ایجاد یک گراف
- یافتن مسیر مطلوب روی گراف با طراحی یک الگوریتم مسیریابی
در مرحلهٔ اول سعی بر این است که فضای پیوسته به فضایی گسسته نگاشته شود. به این ترتیب یک گراف به وجود میآید که در آن (مجموعهٔ رئوس گراف) نمایندهٔ نقاطی از فضای پیوسته و (مجموعهٔ یالهای گراف) نمایندهٔ وجود یا عدم وجود ارتباط بدون واسطه بین دو نقطه از فضای پیوستهاست.



این گراف در مرحلهٔ دوم به عنوان ورودی به یک الگوریتم مسیریابی داده میشود. خروجی این الگوریتم یک آرایهی مرتب از راسها است که برای رسیدن به راس هدف باید آنها را به ترتیب و بدون واسطه طی کرد. الگوریتمهای مسیریابی معمولاً علاوه بر این که میخواهند یک مسیر پیدا کنند، در پی مسیری هستند که بر اساس معیار خاصی (مثلا طول مسیر) بهینه باشد.[4]
الگوریتم
متد مسیریابی با شروع از یک راس و جستجو در راسهای مجاور آن تا زمان رسیدن به راس مقصد، یک گراف را جستجو میکند؛ که معمولاً هدف آن یافتن سریعترین مسیر است. در حقیقت هدف الگوریتم مسیر یابی عموماً یافتن مسیری با کمترین تعداد راس استفاده شده (در گرافهای فاقد وزن)، یا کمترین جمع اوزان مشاهده شده (در گرافهای وزندار) است. به عنوان مثال میتوان گفت که الگوریتم مد نظر، همانند شخصی است که قصد دارد از نقطهای به نقطهٔ دیگری برسد؛ به جای این که این شخص تمام مسیرهای موجود را بررسی کند، در یک مسیر حرکت میکند و فقط زمانی از مسیر خود منحرف میشود که مانعی بر سر راه وی وجود داشته باشد.
دو نکته مهم در مسیر یابی که باید به آن توجه شود عبارتاند از:
- یافتن مسیر بین دو راس در یک گراف
- یافتن کوتاهترین مسیر با کمترین هزینه در یک گراف
الگوریتمهای پایه ای مانند جستجوی اول سطح و جستجوی اول عمق مشکل اول را با بررسی تمام حالتهای موجود بررسی میکنند. به این صورت که با گرفتن یک راس تمام مسیرهای موجود را جستجو میکنند تا به راس هدف برسند. از لحاظ مرتبه زمانی چنین الگوریتمی در زمان طول میکشد که تعداد راسها و تعداد یالها است.

اما مسئلهٔ پیچیدهتر یافتن مسیر بهینه است. راهحل کلی در این موارد استفاده از الگوریتم بلمن-فورد است که پیچیدگی زمانی آن میباشد. الگوریتمهایی مانند Dijkstra و به صورت استراتژیک مسیرها را خرد میکنند.


الگوریتم جستجوی اول عمق

مقالهٔ اصلی: الگوریتم جستجوی اول عمق
الگوریتم جستجوی اول عمق یک روش ساده و در عین حال کارا برای مسیریابی است که در سال ۱۸۸۲ توسط ریاضیدان فرانسوی، چارلز پیر ترما به منظور حل هزارتوها پیشنهاد شد.[5] این الگوریتم بر پایهٔ روش پسگرد استوار است.[6][7]
در این روش یکی از همسایههای گره شروع به صورت دلخواه انتخاب میشود. اگر این گره همسایهای داشته باشد که تا آن لحظه بازدید نشده باشد، الگوریتم به آن همسایه میرود (اگر چند همسایه با این شرایط وجود داشته باشد یکی به دلخواه انتخاب میشود). این روند آنقدر ادامه پیدا میکند تا یکی از دو اتفاق زیر بیفتد:
- گره پایانی مشاهده شود: در این حالت الگوریتم متوقف میشود و مسیر یافته شده به عنوان خروجی بازگردانده میشود.
- الگوریتم به خانهای برسد که همسایهٔ بازدید نشده ندارد: در این حالت الگوریتم یک قدم پسگرد میکند و یکی از گرههایی که در مرحلهٔ قبل بازدید نشده بود را بازدید میکند.[8]
الگوریتم جستجوی اول عمق با وجود سادگی، پایهٔ بسیاری از الگوریتمهای مهم در نظریهٔ گراف است.
این الگوریتم را میتوان به صورت تابع بازگشتی زیر در پایتون پیادهسازی کرد:
def depth_first_search(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
for next in graph[start] - visited:
depth_first_search(graph, next, visited)
return visited
الگوریتم جستجوی اول سطح
مقالهٔ اصلی: الگوریتم جستجوی اول سطح
_for_pathfinding.gif)
این روش نخستین بار در سال ۱۹۵۹ توسط ادوارد مور برای یافتن کوتاهترین مسیر در یک هزارتو معرفی شد.[9] با استفاده از این الگوریتم میتوان کوتاهترین مسیر بین دو راس از یک گراف غیر وزن دار را پیدا کرد.
در این روش که با استفاده از داده ساختار صف پیادهسازی میشود، قسمتی از گراف به عنوان جلودار (frontier) در نظر گرفته میشود. این قسمت از نقطهٔ شروع آغاز به گسترش مینماید و بسته به کاربرد میتواند تا دربرگرفتن تمام گراف یا تا حدی که نقطهٔ پایان مسیر را شامل شود گسترش یابد. در صورت پیمایش تمام گراف، میتوان مسیر بهینه را از نقطهٔ شروع تا هر نقطهٔ دلخواه دیگر را پیدا کرد.
این الگوریتم از یک حلقهٔ تکرار با دو گام زیر تشکیل میشود و تا خالی شدن جلودار ادامه مییابد:
- یک راس از جلودار را انتخاب کن و آن را حذف کن.
- همسایههای راس حذف شده را در صورتی که در مجموع بازدید شدهها (visited) نباشند به جلودار اضافه کن؛ همچنین این راسها را در مجموعهٔ بازدید شدهها قرار بده.
با اجرای این حلقه مولفهٔ همبند گراف که شامل راس شروع است پیمایش میشود. برای ذخیرهٔ مسیر از راس شروع تا هر راس دلخواه، باید حین اضافه کردن همسایهها به جلودار، در جدولی نام راسی که همسایهها از آن منشأ گرفتهاند را نوشت. به این ترتیب پس از رسیدن به راس دلخواه (پایانی) میتوان به صورت بازگشتی مسیری به سمت راس شروع پیدا کرد.
شبه کد الگوریتم به قرار زیر است.
frontier = Queue()
frontier.put(start )
visited = {}
visited[start] = True
while not frontier.empty():
current = frontier.get()
for next in graph.neighbors(current):
if next not in visited:
frontier.put(next)
visited[next] = True
الگوریتم Dijkstra
مقالهٔ اصلی: الگوریتم دایکسترا
الگوریتم Dijkstra برای یافتن کوتاهترین مسیر بین گرهها در یک گراف مورد استفاده قرار میگیرد. این الگوریتم به عنوان مثال، در شبکههای جادهای کاربرد زیادی دارد.[10] این الگوریتم توسط ادسخر دایکسترا در سال ۱۹۵۶ پیشنهاد شد.[11]
این الگوریتم انواع مختلفی دارد. الگوریتم اصلی دایکسترا کوتاهترین مسیر را بین دو گره معین پیدا میکرد،[12] اما یک نوع رایجتر این الگوریتم یک گره منفرد را به عنوان گره "مبدأ" مشخص میکند و کوتاهترین مسیر را از مبدأ مشخص شده تا همهٔ گرههای دیگر در گراف پیدا میکند که به آن "درخت کوتاهترین مسیر (Shortest path tree)" گفته میشود.
برای یک مبدأ مشخص شده در گراف، این الگوریتم کوتاهترین مسیر را بین آن گره و سایر نقاط پیدا میکند.[13] همچنین از این الگوریتم میتوان برای یافتن کوتاهترین مسیر بین دو گره مشخص استفاده کرد، به این صورت که الگوریتم از گره مبدأ آغاز میشود و در زمانی که به گره مقصد رسید متوقف خواهد شد. این الگوریتم کوتاهترین مسیر به شکل گسترده در پروتکلهای مسیریابی در شبکهها کامپیوتری، بهطور مثال در IS-IS یا در OSPF مورد استفاده است.
الگوریتم دایکسترا از برچسبهایی استفاده میکند که اعداد صحیح مثبت یا اعداد حقیقی هستند و کاملاً مرتب شدهاند. اما میتوان آن را به اعدادی که به صورت جزئی (محلی) مرتب هستند نیز تعمیم داد. به این عمومی سازی، الگوریتم کوتاهترین مسیر عمومی دایکسترا گفته میشود.[14]
الگوریتم دایکسترا برای ذخیرهسازی دسترسی به اطلاعات ذخیرهشده، از یک داده ساختار استفاده میکند. الگوریتم اصلی از صف اولویتدار استفاده میکند و پیچیدگی آن (جایی که تعداد گرهها است) میباشد. ایده این الگوریتم در مقالهٔ Leyzorek et al. 1957 نیز ارائه شدهاست. Fredman & Tarjan 1984 با استفاده از یک صف اولویتدار در هرم فیبوناچی پیچیدگی زمان اجرا را به (که تعداد لبهها است) رساندند. این الگوریتم به صورت مجانبی سریعترین الگوریتم یافتن کوتاهترین مسیر از یک مبدأ برای یک گراف جهت دار با وزنهای غیر منفی بدون محدودیت شناخته شدهاست.




الگوریتم
گرهی که الگوریتم از آن آغاز میشود گره اولیه نامیده میشود. طول مسیر گره Y را فاصلهٔ گره Y تا گره اولیه (مبدأ) قرار میدهیم. الگوریتم دایکسترا مقادیر اولیهای (معمولا صفر برای گره اولیه و بینهایت برای سایر گرهها) را به گرهها نسبت میدهد و در هر مرحله آن را بهبود میبخشد.
- در ابتدا همهٔ گرهها را «بازدیدنشده» نشانهگذاری میکنیم. سپس مجموعهای از همهٔ گرههای بازدید نشده میسازیم و آن را مجموعه «بازدیدنشده» نامگذاری میکنیم.
- به هر گره یک مقدار فاصله آزمایشی اختصاص میدهیم. آن را برای گره اولیه صفر و برای تمام گرههای دیگر بینهایت قرار میدهیم. گره اولیه را به عنوان گره فعلی در نظر میگیریم.[15]
- برای گره فعلی، همهٔ گرههای بازدید نشدهٔ همسایهٔ آن را در نظر میگیریم و فاصلهٔ آنها را از گره فعلی حساب میکنیم. فاصلهٔ تازه محاسبه شده را با مقدار تعیین شدهٔ فعلی مقایسه میکنیم و کوچکترین آنها را به آن گره اختصاص میدهیم. به عنوان مثال، اگر گره فعلی A با فاصلهٔ 6 علامتگذاری شود و یالی که آن را به B متصل میکند دارای طول 2 باشد، در این صورت فاصله تا B از A برابر 6 + 2 = 8 خواهد بود. اگر قبلاً B با مسافت بیشتر از 8 مشخص شده بود، آن را به 8 تغییر میدهیم. در غیر این صورت، مقدار فعلی حفظ خواهد شد.
- وقتی همهٔ همسایگان گره فعلی که «دیدهنشده» نشانهگذاری شده بودند را پیمایش کردیم و به آنها یک فاصله اختصاص دادیم، گره فعلی را «بازدیدشده» علامتگذاری میکنیم و آن را از مجموعه «بازدیدنشده» خارج میکنیم. گره بازدیدشده هرگز دوباره بررسی نمیشود.
- اگر گره مقصد مورد بازدید قرار گرفته شده باشد (هنگام پیدا کردن مسیری بین دو گره خاص) یا اگر کوچکترین فاصله در بین گرههای موجود در مجموعهٔ بازدیدنشده بینهایت باشد (هنگام پیدا کردن یک گذر کامل؛ وقتی اتفاق میافتد که هیچ ارتباطی بین آن گرهها و گره اولیه وجود ندارد و گرهها بازدیدنشده باقی میمانند)، دیگر الگوریتم را ادامه نمیدهیم. الگوریتم به پایان رسیدهاست.
- در غیر این صورت، گره بازدیدنشده را که با کمترین فاصله مشخص شدهاست، انتخاب میکنیم، آن را به عنوان «گره فعلی» جدید تنظیم میکنیم و به مرحله 3 برمیگردیم.
هنگام پیدا کردن یک مسیر، لازم نیست صبر کنیم تا گره مقصد مانند «فوق» بازدید شود: الگوریتم میتواند هنگامی که گره مقصد کمترین فاصله را بین همهٔ گرههای «بازدیدنشده» داشته باشد متوقف شود (و بنابراین این گره میتواند به عنوان گره «فعلی» بعد از گره مبدأ مورد استفاده قرار گیرد).
شرح اجرا

فرض کنید میخواهیم کوتاهترین مسیر بین دو نقطه روی نقشه را پیدا کنیم، یکی از این دو نقطه را نقطهٔ شروع و دیگری را به عنوان مقصد در نظر میگیریم. الگوریتم دایکسترا در ابتدا فاصلهٔ هر نقطهٔ تقاطع تا مبدأ روی نقشه را با بینهایت نشانه گذاری میکند. این کار به این معنی نیست که فاصلهها بینهایت هستند، بلکه به این معنا است که این نقاط تقاطع هنوز بازدید نشدهاند (روشهایی نیز وجود دارند که تقاطعهای بازدید نشده را در ابتدا نشانه گذاری نمیکنند). اکنون در هر تکرار یکی از این نقاط تقاطع را انتخاب میکنیم. در اولین مرحله، تقاطع فعلی، نقطهٔ شروع بوده و فاصله تا آن صفر خواهد بود (پس این نقطه را با صفر نشانهگذاری میکنیم). در مراحل بعد، نقطهای که روی آن قرار داریم نزدیکترین نقطه به مبدأ خواهد بود (پیدا کردن آن نیز کاری آسان خواهد بود).
از تقاطع فعلی، فاصلهٔ تمام نقاط تقاطعی که به آن بهطور مستقیم متصل هستند و بازدید نشدهاند را بهروزرسانی میکنیم. این کار را به این صورت انجام میدهیم که مجموع فاصلهٔ نقطهٔ تقاطع مورد نظر با تقاطع فعلی را با نشانهای که برای تقاطع فعلی در نظر گرفتهایم حساب میکنیم، پس از آن اگر مجموع حسابشده از نشانهٔ آن تقاطع بازدیدنشده کمتر بود آن را با مقدار جدید نشانهگذاری میکنیم. بعد از اینکه مسافتها را برای هر تقاطع همسایه بهروزرسانی کردیم، تقاطع فعلی را به عنوان بازدیدشده علامتگذاری میکنیم و یک تقاطع بازدید نشده با حداقل فاصله (از نقطهٔ شروع) -یا کمترین عدد نشانهگذاری شده روی آن- را به عنوان تقاطع فعلی انتخاب میکنیم. تقاطعهایی که به عنوان بازدیدشده هستند با کوتاهترین مسیر از نقطهٔ مبدأ تا آن برچسب خوردهاند و قابل بازنگری یا بازگشت به آن نخواهند بود.
این روند یعنی به روز رسانی تقاطعهای همسایه با کمترین فاصلهٔ آنها تا مبدأ، نشانهگذاری تقاطعی که روی آن بودیم به عنوان بازدیدشده و سپس انتخاب نزدیکترین تقاطع همسایه به عنوان تقاطع بعدی را ادامه میدهیم تا زمانی که نقطهٔ مقصد مورد نظر را به عنوان بازدیدشده مشخص کنیم. هنگامی که مقصد را به عنوان بازدیدشده مشخص کردیم کوتاهترین مسیر از نقطهٔ مبدأ تا آن را تعیین کردهایم و میتوانیم مسیر خود را به عقب با دنبال کردن جهت معکوس پیکانها ردیابی کنیم. در اجرای الگوریتم، این کار معمولاً بدین صورت انجام میشود که از نقطهٔ مقصد شروع به دنبال کردن والدین آن و پس از آن والدین نقطهٔ بعدی میکنیم تا به نقطهٔ مبدأ برسیم. به همین دلیل والدین هر گره را نیز در هر مرحله باید داشته باشیم و بهروز کنیم.
این الگوریتم همانطور که انتظار میرود هیچ تلاشی برای «کاوش» مستقیم به سمت نقطهٔ مقصد انجام نمیدهد. در عوض، تنها نکتهٔ مورد نظر برای تعیین نقطهٔ تقاطع بعدی، فاصله آن از نقطهٔ شروع است. این نکته نیز ممکن است یکی از نقاط ضعف الگوریتم را نشان دهد، کندی نسبی آن در برخی توپولوژیها.
شبه کد
در الگوریتم زیر، کد u ← vertex در Q با حداقل فاصله [u]، گره u را در مجموعه گرههای Q جست و جو میکند که حداقل فاصلهٔ آن [dist[u است. (length(u, v فاصلهٔ بین دو گره همسایه u و v را برمیگرداند. متغیر alt در خط 18 طول مسیر از گره ریشه (نقطهٔ مبدأ) تا گره همسایه v است به طوری که این مسیر از گره u عبور کند. اگر این مسیر محاسبه شده کوتاهتر از کوتاهترین مسیری باشد که برای v ثبت شدهاست، مسیر محاسبهشده در متغیر alt با مسیر قبلی جایگزین میشود. آرایه prev شامل اشارهگرها به گره بعدی است تا کوتاهترین مسیر به مبدأ قابل بازیابی باشد.
1 function Dijkstra(Graph, source):
2
3 create vertex set Q
4
5 for each vertex v in Graph:
6 dist[v] ← INFINITY
7 prev[v] ← UNDEFINED
8 add v to Q
9 dist[source] ← 0
10
11 while Q is not empty:
12 u ← vertex in Q with min dist[u]
13
14 remove u from Q
15
16 for each neighbor v of u: // only v that are still in Q
17 alt ← dist[u] + length(u, v)
18 if alt < dist[v]:
19 dist[v] ← alt
20 prev[v] ← u
21
22 return dist[], prev[]در صورتی که فقط به کوتاهترین مسیر بین گره مبدأ و مقصد علاقهمند باشیم، میتوانیم جستجو را پس از خط 15 با این شرط که u = target خاتمه دهیم. اکنون میتوانیم کوتاهترین مسیر از مبدأ به مقصد را با یک تکرار معکوس به شکل زیر بخوانیم:
1 S ← empty sequence
2 u ← target
3 if prev[u] is defined or u = source: // Do something only if the vertex is reachable
4 while u is defined: // Construct the shortest path with a stack S
5 insert u at the beginning of S // Push the vertex onto the stack
6 u ← prev[u] // Traverse from target to sourceحالا دنبالهٔ S لیستی از رئوسی است که یکی از کوتاهترین مسیرها از مبدأ به مقصد را تشکیل میدهند. البته اگر هیچ مسیری وجود نداشته باشد، دنباله خالی خواهد بود.[16]
یک مسئلهٔ کلی تر این است که همهٔ کوتاهترین مسیرها را بین مبدأ و مقصد پیدا کنیم (ممکن است چندین مسیر مختلف با طول یکسان وجود داشته باشد). در این صورت به جای این که فقط یک گره را هر بار در آرایه []prev ذخیره کنیم، تمام گرههایی که شرایط مورد نظر در الگوریتم را برآورده میسازد در آن ذخیره میکنیم. به عنوان مثال، اگر هم گره r و هم مبدأ، متصل به گره مقصد باشند و هر دوی آنها شامل کوتاهترین مسیرهای مختلف به گره مقصد باشند، هر دو را به آرایه [prev[target اضافه میکنیم. وقتی که الگوریتم به پایان رسید، []prev در واقع یک ساختار داده خواهد بود که زیرمجموعهای از گراف اصلی است به طوری که برخی از یالهای آن برداشته شدهاست. ویژگی اصلی این ساختار داده این خواهد بود که اگر الگوریتم برای همهٔ گرهها به عنوان گره مبدأ اجرا شود، آنگاه هر مسیری از آن گره به هر گره دیگر در گراف جدید، کوتاهترین مسیر بین آن گرهها در گراف اصلی خواهد بود، و تمام مسیرهایی از آن طول در گراف اصلی در گراف جدید نیز موجود است. سپس برای یافتن همه این کوتاهترین مسیرها بین دو گره داده شده، از الگوریتمی برای یافتن مسیر در گراف جدید مانند جستجوی اول عمق استفاده خواهیم کرد.
الگوریتم بلمن-فورد
مقالهٔ اصلی: الگوریتم بلمن-فورد
مقدمه
الگوریتم Bellman-Ford الگوریتمی برای پیدا کردن کوتاهترین مسیر از یک راس گراف به عنوان منبع به کلیه راسهای دیگر در یک گراف وزندار است.[17] این الگوریتم در حل یک مسئله مشخص از الگوریتم دکسترا کندتر است، اما برای حل مسائل بیشتری کاربرد دارد، زیرا این قابلیت را دارد که برای گرافهایی با وزن منفی نیز استفاده شود. این الگوریتم برای اولین بار توسط آلفونسو شیمبل ارائه شدهاست، اما به نام ریچارد بلمن و لستر فورد جونیور نامگذاری شدهاست که به ترتیب در سال ۱۹۵۸ و ۱۹۵۶ این الگوریتم را منتشر کردند.[18] ادوارد اف. مور نیز در سال ۱۹۵۷ همین الگوریتم را منتشر کرد و به همین دلیل گاهی اوقات الگوریتم بلمن-فورد-مور نیز نامیده میشود.[17]
یالهای منفی گرافها در بسیاری از مسائل کاربرد دارد، از این رو این الگوریتم میتواند از جهت کمک به حل این نوع از مسائل بسیار سودمند باشد. [19] اگر یک گراف شامل یک «دور منفی» (یعنی دوری که مجموع وزن یالهای آن به یک مقدار منفی برسد) که از مبدأ قابل دسترسی باشد، کوتاهترین مسیر وجود ندارد: هر مسیری که دارای یک راس در دور منفی باشد میتواند با هر بار پیمایش دور منفی موجود در گراف به مسیر کوتاه تری تبدیل شود. در چنین حالتی، الگوریتم بلمن-فورد میتواند دور منفی را شناسایی و گزارش کند.[20] [21]
الگوریتم
مانند الگوریتم دایکسترا، بلمن-فورد با استفاده از روش «ریلکس» کردن (relaxation) پیش میرود، که در آن تقریب فاصلهٔ صحیح با فواصل بهتر در طول الگوریتم جایگزین میشود تا اینکه در نهایت به بهترین جواب برسد. در هر دو الگوریتم، فاصلهٔ تقریبی مبدأ با هر راس در گراف همیشه فراتر از فاصلهٔ واقعی است و در طول اجرا با حداقل مقدار از بین مقدار قدیمی آن و مسیر تازه پیدا شده جایگزین میشود. با این حال، الگوریتم دایکسترا از صف اولویت دار برای انتخاب حریصانهی نزدیکترین راسی که هنوز پردازش نشدهاست استفاده میکند و همین روند را برای تمامی یالهای خروجی راسها انجام میدهد. در مقابل، الگوریتم بلمن-فورد به راحتی تمام یالها را «ریلکس» میکند و ریلکس کردن را بار انجام میدهد، که در آن تعداد راسهای موجود در گراف است. در هر یک از این تکرارها تعداد راسها با فاصلهٔ درست از مبدأ رشد میکند، که در نهایت منجر به این میشود که فاصله همه راسها از مبدأ بهطور صحیح محاسبه شود. این روش اجازه میدهد تا الگوریتم بلمن-فورد برای طیف گستردهتری از گرافها به عنوان ورودی اجرا شود.

پیچیدگی زمانی اجرا ی الگوریتم بلمن - فورد است، که در آن و به ترتیب تعداد راسها و یالهای گراف هستند.

1function BellmanFord(list vertices, list edges, vertex source) is
2 ::distance[], predecessor[]
3
4 // This implementation takes in a graph, represented as
5 // lists of vertices and edges, and fills two arrays
6 // (distance and predecessor) about the shortest path
7 // from the source to each vertex
8 // Step 1: initialize graph
9 for each vertex v in vertices do
10 distance[v] := inf // Initialize the distance to all vertices to infinity
11 predecessor[v] := null // And having a null predecessor
12 distance[source] := 0 // The distance from the source to itself is, of course, zero
13
14
15 // Step 2: relax edges repeatedly
16
17 for i from 1 to size(vertices)−1 do //just |V|−1 repetitions; i is never referenced
18 for each edge (u, v) with weight w in edges do
19 if distance[u] + w < distance[v] then
20 distance[v] := distance[u] + w
21 predecessor[v] := u
22
23
24 // Step 3: check for negative-weight cycles
25
26 for each edge (u, v) with weight w in edges do
27 if distance[u] + w < distance[v] then
28 error "Graph contains a negative-weight cycle"
29
30
31 return distance[], predecessor[]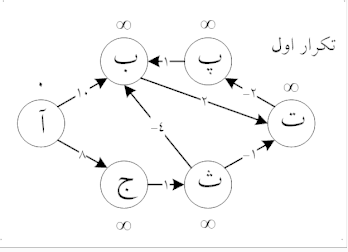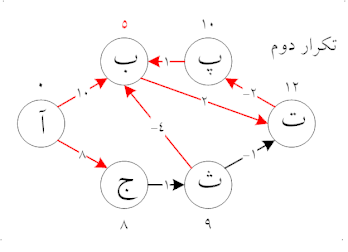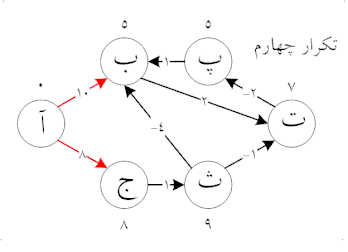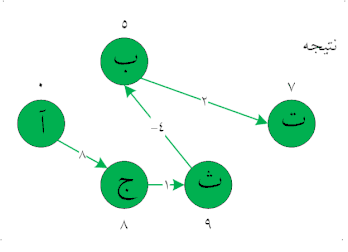
به عبارت ساده، این الگوریتم در ابتدای کار فاصلهٔ مبدأ را برابر صفر و همه راسهای دیگر گراف را بینهایت قرار میدهد. سپس برای همه یالها، اگر با در نظر گرفتن آن یال فاصلهٔ مقصد کاهش پیدا کند، فاصله به مقدار کمتر جدید به روز میشود. در iاُمین بار تکرار الگوریتم که یالها مورد بررسی قرار میگیرند، این الگوریتم تمام مسیرهای با طول i یال (و احتمالاً برخی از مسیرهای طولانیتر از i یال) پیدا میکند. از آنجایی که طولانیترین مسیر ممکن بدون دور میتواند شامل یال باشد، یالها باید بار بررسی شوند تا مطمئن شویم که کوتاهترین مسیر برای همه راسها پیدا شدهاست. بررسی نهایی برای تمامی یالها انجام میشود و اگر فاصلهای به روز شود، مسیری به طول یال پیدا شدهاست که تنها در صورت وجود حداقل یک دور با وزن منفی در گراف میتواند رخ دهد.
الگوریتم *A
مقاله اصلی: الگوریتم *A
این الگوریتم در ابتدا توسط پیتر ای هارت (Peter E. Hart)، نیلز جان نیلسون (Nils John Nilsson) و برترام رافائل (Bertram Raphael) در سال ۱۹۶۸ میلادی ارائه و شرح داده شد. در واقع این الگوریتم ترکیبی از الگوریتم Dijkstra و الگوریتم جستجوی ابتدا-بهترینِ حریصانه است و در عین حال که کوتاهترین مسیر را مییابد (البته در مواردی که خانههای بسته -خانههایی که غیرقابل عبورند- وجود دارد این ویژگی تضمین شده نیست)، از هر دو سریعتر کار میکند.[22]
در این الگوریتم، ابتدا دو لیست تعریف میکنیم؛ لیست باز (open list) و لیست بسته (closed list). سپس نقطه مبدأ را به لیست بسته اضافه میکنیم و در هر مرحله راسهای قابل تردد همسایهٔ راس فعلی را به لیست باز اضافه میکنیم. حال باید دو تابع تعریف کنیم:[23]
- تابع G: هزینهٔ رسیدن تا مکان فعلی (مقدار یالهای طی شده از مبدأ تا راس فعلی)
- تابع H: هیوریستیک یا تخمین هزینهٔ رسیدن از راس فعلی تا مقصد
حال اگر تعریف کنیم: (F(node) = G(node) + H(node، آنگاه این تابع برآورد کمهزینهترین مسیر از node به مقصد است. برای محاسبهٔ G مقدار G والد (آخرین راس قبل از راس فعلی که از آن گذشتهایم) آن راس را یک واحد بیشتر میکنیم. برای حساب کردن H راههای مختلفی وجود دارد مانند روش فاصلهٔ منهتن (Manhattan distance method)، روش فاصلهٔ قطری (Diagonal distance method)، روش فاصلهٔ اقلیدسی (Euclidean distance method) و …[24]
این الگوریتم این گونه کار میکند که در هر مرحله به کمهزینهترین راس موجود در لیست باز میرود و هر همسایه راس فعلی مانند T سه حالت دارد:
- اگر T در لیست بسته بود، کاری نمیکند.
- اگر T در لیست باز بود، با G و H جدید Fاش را بهروزرسانی میکند.
- اگر T در هیچکدام نبود، به لیست باز اضافه شده و مقدار توابع G و H و Fاش محاسبه میشود.[25][22]
شبه کد الگوریتم *A به صورت زیر است:
function A*(start, goal)
closed = empty set
q = makequeue(path(start))
while q is not empty do
p = removefirst(q)
x = lastnode(p)
if x in closed then
end if
if x = goal then
return p
end if
add x to closed
for y := successor(x) do
enqueue(p,q,y)
end for
return Failure
end while
end function
الگوریتم نمونه
حال برای درک بهتر الگوریتمهای مسیریابی میتوان به مثال زیر توجه کرد. در نقشهٔ زیر x نماد مکانهای بسته یا دیوار، s محل شروع، o نقطهٔ پایان و _ مکانهای باز نقشه را نشان میدهند.
1 2 3 4 5 6 7 8
X X X X X X X X X X
X _ _ _ X X _ X _ X 1
X _ X _ _ X _ _ _ X 2
X S X X _ _ _ X _ X 3
X _ X _ _ X _ _ _ X 4
X _ _ _ X X _ X _ X 5
X _ X _ _ X _ X _ X 6
X _ X X _ _ _ X _ X 7
X _ _ O _ X _ _ _ X 8
X X X X X X X X X X
برای شروع به یک لیست از مختصاتها نیاز است که در این مورد از یک صف استفاده میشود. این صف ابتدا به وسیلهٔ مختصات نقطهٔ نهایی مقدار دهی اولیه میشود. همچنین به هر کدام از اعضای صف یک شمارنده تخصیص داده میشود. در مثال مورد بررسی، صف با ((۳٬۸٬۰)) شروع میشود.
سپس بر روی تمام اعضای صف پیمایش انجام میشود و اعمال زیر برای هر عضو انجام میشود.
- یک لیست از چهار عنصر مجاور آن تشکیل داده میشود که یرای هر عنصر متغیر شمارندهٔ آن، شمارندهٔ عنصر در صف به علاوهٔ یک میباشد؛ که در مثال بالا این لیست به صورت ((۲٬۸٬۱),(۳٬۷٬۱),(۴٬۸٬۱),(۳٬۹٬۱)) است.
- حال عناصر موجود در این لیست جدید بررسی میشود که اگر آن عنصر ذیوار بود یا در لیست اصلی مختصاتی مشابه با شمارندهٔ کمتر وجود داشت حذف میشود.
- عناصر باقیمانده به صف اصلی اضافه میشوند.
- عنصر بعدی بررسی میشود.
این کار را تا زمانی انجام میپذیرد که نقطهٔ شروع مشاهده شود. هنگامی که به نقطه شروع برسیم مشاهده میشود که نقاطی که در صف هستند، یک مقدار شمارنده به آنها تخصیص داده شدهاست. در نقشه زیر این موضوع مشخص است.
1 2 3 4 5 6 7 8
X X X X X X X X X X
X _ _ _ X X _ X _ X 1
X _ X _ _ X _ _ _ X 2
X S X X _ _ _ X _ X 3
X 6 X 6 _ X _ _ _ X 4
X 5 6 5 X X 6 X _ X 5
X 4 X 4 3 X 5 X _ X 6
X 3 X X 2 3 4 X _ X 7
X 2 1 0 1 X 5 6 _ X 8
X X X X X X X X X X
حال از نقطهٔ S پیمایش شروع میشود و در هر مرحله از بین مختصاتهای مجاور هر نقطه، به نقطه ای با کمترین مقدار شمارنده حرکت میکنیم.
مقایسهٔ الگوریتمها
در جدول زیر، الگوریتمهای شاخص مسیریابی از جهت پیچیدگی زمانی و مورد کاربرد با یکدیگر مقایسه شدهاند.
| الگوریتم | پیچیدگی زمانی | توضیحات |
|---|---|---|
| جستجوی اول عمق | برای گرافهای بدون وزن | |
| جستجوی اول سطح | برای گرافهای بدون وزن | |
| دایکسترا | برای گرافهای وزندار بدون دور منفی | |
| بلمن-فورد | برای گرافهای وزندار با قابلیت اعمال بر گرافهای دارای دور منفی | |
| *A | برای گرافهای وزندار بدون دور منفی |




کاربردهای مسیریابی
- مسیریابی در شبکههای کامپیوتری: برای انتقال داده بین دو گره شبکه از الگوریتمهای مسیریابی برای پیدا کردن بهترین مسیر بین دو گره استفاده میشود.
- بازیهای کامپیوتری: الگوریتمهای مسیریابی در واقع هستهٔ هر سیستم حرکتی مجهز به هوش مصنوعی هستند. الگوریتمهای مسیریابی در بازیهای کامپیوتری وظیفه دارند تا بین هر دو نقطهٔ روی مختصات بازی بهترین مسیر را پیدا کنند.[26]
- نقشههای آنلاین: استفادهٔ این برنامهها از مسیریابی در زندگی روزمره بسیار زیاد است. الگوریتمهای مسیریابی باید بتوانند در هر زمانی با در نظر گرفتن متغیرهای مختلفی (اعم از ترافیک، مسیرهای مسدودشده و …) مسیرهای مناسب را به کاربران پیشنهاد دهند.[27]
- ساخت و ساز راهها: یکی از کاربردهای مسیریابی پیدا کردن جادهها است. این امر به این شکل انجام میگیرد که مسیرهای تصادفی بین مکانهایی که مردم علاقه زیادی به استفاده از آنها دارند انتخاب میشود. سپس با توجه به اینکه کدام مسیرها فضای بیشتری را روی نقشه پوشش میدهند، جادهها روی آنها بنا میشوند. از این الگوریتم برای ساختن انواع راهها مانند بزرگراهها، جادههای بین شهری، راههای خاکی و … استفاده میشود. یکی از مهمترین کاربردهای این الگوریتم در ساختن جادههای کوهستانی است که برای پرهیز از شیبهای تند استفاده میشود.[28]
- شهرسازی: مناطقی که محل تقاطع چند مسیر مختلف هستند محل مناسبی برای ساختن شهرها محسوب میشوند.[28]
- تجزیه و تحلیل زمین: با استفاده از همان رویکرد راهسازی، میتوان از مسیریابی استفاده کرد تا مشخص شود که چه مناطقی احتمالاً بیشتر در مسیر رفت و آمد قرار دارند. این نقاط و مناطق نزدیک به آنها، از نظر استراتژیک دارای اهمیت هستند.[28]
- مکان یابی در محیطهای رزمی: از همان روش بالا برای تجزیه و تحلیل زمین، با تجزیه و تحلیل بیشتر مسیر، میتوانیم مکانهایی را در طول مسیر پیدا کنیم که برای دشمن تا N قدم بعدی در مسیر متنهی به آن قابل رویت نباشد. قرار دادن کمین در یکی از این نقاط بدان معنی است که دشمن تا زمانی که در فاصله N قرار نگیرید، شما را نمیبیند، بنابراین میتوان با یک نیروی بزرگ کمین کرد.[28]
- رباتیک: از جمله مسائل مهم در رباتهای متحرک مسیریابی میباشد که هوش مصنوعی به آن ورود کردهاست.[29] مریخنوردها رباتهایی هستند که از الگوریتمهای مسیریابی استفاده میکنند.
 مریخنوردها از الگوریتمهای مسیریابی استفاده میکنند.
مریخنوردها از الگوریتمهای مسیریابی استفاده میکنند.
منابع
- "Pathfinding". Wikipedia. 2019-05-02.
- Alexander Schrijver. «On the History of the Shortest Path Problem» (PDF).
- Abd Algfoor, Zeyad; Sunar, Mohd Shahrizal; Kolivand, Hoshang (2015). "A Comprehensive Study on Pathfinding Techniques for Robotics and Video Games". International Journal of Computer Games Technology. 2015: 1–11. doi:10.1155/2015/736138. ISSN 1687-7047.
- Patrick Lester (2005). "A* Pathfinding for Beginners" (PDF).
- j2kun (2013-01-22). "Depth- and Breadth-First Search". Math ∩ Programming. Retrieved 2019-12-05.
- «Depth-First Search (DFS) | Brilliant Math & Science Wiki». brilliant.org (به انگلیسی). دریافتشده در ۲۰۱۹-۱۲-۰۵.
- «3.5.2 Depth-First Search‣ 3.5 Uninformed Search Strategies ‣ Chapter 3 Searching for Solutions ‣ Artificial Intelligence: Foundations of Computational Agents, 2nd Edition». artint.info. دریافتشده در ۲۰۱۹-۱۲-۰۵.
- Bettilyon, Tyler Elliot (2019-04-04). "Breadth First Search and Depth First Search". Medium. Retrieved 2019-12-05.
- Moore, Edward F. (1959). "The shortest path through a maze". Proceedings of the International Symposium on the Theory of Switching. Harvard University Press. pp. 285–292
- «OSPF Incremental SPF». ۱۱ آذر ۱۳۹۸.
- «Edsger Wybe Dijkstra». A.M. Turing Award.
- Dijkstra1959 (PDF).
- Algorithms and Data Structures: The Basic Toolbox.
- «Generic Dijkstra for Optical Networks».
- {{یادکرد ژورنال |vauthors=Michael Fu, Saul Gass |تاریخ=2013 |عنوان=Encyclopedia of Operations Research and Management Science| |doi=10.1007/978-1-4419-1153-7}
- Priority Queues and Dijkstra’s Algorithm — UTCS Technical Report TR-07-54 — 12 October 2007 (PDF).
- Bang-Jensen & Gutin (2000)
- Schrijver (2005)
- Sedgewick (2002).
- Bang-Jensen & Gutin (2000)
- Kleinberg & Tardos (2006).
- Azad Noori, Farzad Moradi. «Simulation and Comparison of Efficency in Pathfinding algorithms in Games».
- «What is the A* algorithm».
- «Amit's Thoughts on Pathfinding/Heuristics».
- Ray Wenderlich. «Introduction to A* pathfinding».
- "مسیریابی در بازیهای کامپیوتری" (به English).
- «مسیریابی در نقشههای آنلاین». ۱۱ آذر ۱۳۹۸.
- «کاربردهای مسیریابی». ۱۱ آذر ۱۳۹۸.
- «Robotics» (PDF).
