دستهنما
یک کلادوگرام یک دیاگرام است که رابطه اجدادی بین گونه و تکامل درخت حیات را نمایش میدهد. اگر چه به صورت سنتی چنین کلادوگرامهایی بر اساس مشخصات مورفولوژی مشخص میشدند اما دادههای دنباله دیانای، آرانای و فیلوژنتیک محاسباتی به صورت معمولتر در تولید کلادوگرامها نقش دارند.

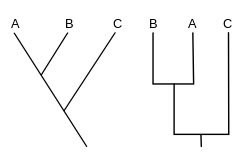
تولید یک کلادوگرام
یک الگوریتم حریصانه برای تولید یک کلادوگرام این طور هست که:
- جمعآوری و سازماندهی کلادوگرامها
- فراهم آوردن کلادوگرامهای ممکن
- انتخاب بهترین کلادوگرام
مرحله ۱: جمعآوری و سازماندهی دادهها
یک آنالیز کلادیستیک با دادههای زیر شروع میشود:
- یک فهرست از تکساها (برای نمونه گونهها) که سازماندهی شدهاند.
- یک فهرست از کاراکترها برای مقایسه شدن.
- برای هر تاکسون مقادیر هر یک از کاراکترهای فهرستشده.
برای نمونه اگر، ۲۰ گونه از پرندگان را آنالیز کنیم، دادههای ممکن بهصورت زیر میباشد:
- فهرست ۲۰ گونه
- کاراکترهایی همانند دنباله ژنوم، آناتومی اسکلتی، پروسسهای بیوشیمیایی و رنگآمیزی پرها میباشد.
- برای هر ۲۰ گونه دنباله ژنوم، آناتومی اسکلتی، پروسسهای بیوشیمیایی و رنگآمیزی پر مخصوص به آن.
تمام دادهها سپس در ماتریس کاراکتر-تاکسون جمعآوری میشوند که اساس انجام آنالیزهای فیلوژنتیکی میباشد.
دادههای مورفولوژیکی در مقابل دادههای مولکولی
کاراکترهای استفادهشده برای ایجاد یک کلادوگرام میتوانند بهطور کلی در هر یک از مورفولوژیها سازماندهی شوند (synapsid skull، warm blooded، notochord، unicellular، غیره) یا مولکولی (DNA، RNA، یا دیگر اطلاعات ژنتیکی). قبل از ظهور دنبالههای DNA تمام آنالیزهای کلادوگرام دادههای مورفولوژی را استفاده میکردند. همانطور که تعیین توالی دیانای ارزانتر و سادهتر گردید، فیلوژنتیک ملکولی روش مشهورتر و مشهورتری برای ایجاد تکامل نژادی شد.[2] با استفاده از معیار پارسیمونی که یکی از چندین روش برای پی بردن به تکامل نژادی از دادههای مولکولی میباشد. درستنمایی بیشینه واستنباط بیزی، که مدلهای صریحی از تکامل دنباله تأسیس میکنند، روشهای non-Hennigian برای ارزیابی دادهها ای دنباله میباشند. روشهای قدرتمند دیگر از تکامل نژادی با استفاده از ژنوم retrotransposon marker میباشد که به مسئلهٔ reversion که دادههای دنباله را مبتلا میکند کمتر مستعد میباشد. آنها به صورت معمول فرض میشوند که وقوع کمتری از تشابه ساختمانی دارند زیرا سابقاً تصور میشد که اجتماعشان با ژنومها کاملاً تصادفی است. بهر حال لااقل بنظر میرسد در بعضی مواقع این چنین نمیباشد. بصورت مطلوب، مورفولوژی، مولکولی و دیگر فیلوژنهای ممکن باید درون یک آنالیز از total evidence ترکیب شوند: تمام آنها منابع ذاتی متفاوتی از خطاها دارند. برای نمونه همگرایی کاراکتر (فرگشت همگرا) در دادههای مورفولوژی نسبت به دادههای دنباله مولکولی معمولتر است، اما معکوس کاراکتر که غیرقابل فهم هستند در حروف معمولترند (ببینید long branch attraction را). تشابه ساختمانی مورفولوژیکی میتواند بهطور معمول همینطور تشخیص داده شود. اگر وضعیت کاراکترها با جزئیات تعریف شده باشد.
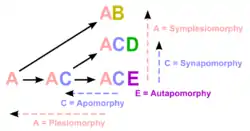
Plesiomorphies and synapomorphies
محققان باید تصمیم بگیرند که حالت کاراکتر باید قبل از آخرین جد مشترک از گروه گونهها باشد (plesiomorphies) یا اینکه در آخرین جد مشترک نمایش داده شوند (synapomorphies)، و بنابراین توسط یکی یا بیشتر از outgroupsها انجام گیرد. انتخاب یکی از outgroupها یکی از مراحل اساسی در آنالیز کلادیستیک میباشد، زیرا outgroupهای متفاوت میتوانند درختهایی با توپولوژیهای بسیار متفاوت تولید کنند.
اجتناب از تشابه ساختمانی
یک فرگشت همگرا یک مشخصه است که به وسیلهٔ گونههای متفاوت بعلت بعضی از مسایل بجز جد مشترک به اشتراک گذاشته شدهاست. دو نوع اصلی از هموپلاسی همگرایی (وجود مشخصه یکسان در حداقل دو جد مجزا) و معکوس (بازگشت به یک کاکتر اجدادی) میباشد. استفاده از هموپلاسی در هنگام ایجاد یک کلادوگرام اجتناب ناپذیر است اما در حد امکان اجتناب شدهاست. یک نمونه شناخته شده از هموپلاسی بعلت همگرایی تکامل مشخصه "presence of wings" خواهد بود. با توجه به اینکه بال پرندگان، خفاش و حشرات تابع یکسانی را بکار میگیرند، هر تغییر مستقلانه، میتواند به وسیلهٔ آناتومی شان دیده شود. اگر یک پرنده، خفاش و دیگر حشرات بالدار برای مسئله "presence of wings" امتیاز بندی شده باشند، یک هموپلاسی در دیتا ست، واین آنالیز را گیج خواهد کرد، نتایج احتمالی را در یک سناریوی غلط معرفی خواهد کرد. آن ممکن است که غیرقابل اجتناب باشد که کاراکترهایی که تعریفشان مبهم است را تعریف کنیم. هموپلاسیها میتوانند اغلب آشکارا در در دیتاسِتهای مورفولوژیکی بهوسیلهٔ تعریف دقیق کاراکترها و افزایش تعدادشان اجتناب گردند، در غیر این صورت کاراکترها ممکن است به تمام کل taxaها انجام نگیرد؛ با ادامهدادن به مثال بالها، حضور بالها به سختی کاراکتر مفیدی خواهد بود اگر یک phylogeny را از تمام Metazoa جستجو کنیم، بهطوریکه هیچکدام از اینها اصلاً بالی ندارند؛ بنابراین انتخاب دقیق و تعریف کاراکترها یک عنصر اساسی در آنالیز کلادیستیکی میباشد. با یک مجموعه کاراکتر و outgroup ناقص، هیچ روشی برای تولید نمایش فیلوژنی به صورت واقعی وجود ندارد.
مرحله ۲: فراهم کردن کلادوگرامهای ممکن
وقتی تعداد کمی از گونهها سازمان دهی شدهاند میتوان این مرحله را به صورت دستی انجام داد، اما در حالات دیگر نیاز به برنامه کامپیوتری میباشد. امتیازاتی از برنامههای کامپیوتر در دسترس برای پشتیبانی از کلادیستیکها در دسترس میباشند. برای اطلاعات بیشتر دربارهٔ برنامههای کامپیوتری تولید درخت درخت فیلوژنتیک را ببینید. بهدلیل اینکه تعداد کل کلادوگرامهای ممکن براساس تعداد گونهها به صورت فاکتوریلی رشد میکنند، ارزیابی هر کلادوگرام شهودی برای برنامههای کامپیوتری غیرممکن میباشد. یک برنامهٔ کلادیستیک معمول با استفاده از تکنیکهای هیوریستیک شروع میگردد تا یک تعداد کم از کلادوگرامهای کاندیدا را ایجاد نماید. تعدادی از برنامههای کلادیستیک سپس جستجویی با مراحل زیر را ادامه میدهند:
- ارزیابی کلادوگرامهای ممکن با استفاده از مقایسه دادههای کاراکتری آنها
- مشخص کردن بهترین کاندیداهایی که بیشترین سازگاری را با دادههای کاراکتری دارند
- ایجاد کاندیداهای اضافه بهوسیلهٔ ایجاد نمونههای مختلف از هر یک از بهترین کاندیداها در مرحلهٔ قبلی
- با استفاده از هیوریستیک ایجاد چندین کلادوگرام کاندیدای جدید با استفاده از کاندیداهای قبلی
- تکرار این مراحل تا اینکه کلادوگرامهای با بهترینها متوقف شوند
برنامههای کامپیوتری که کلادوگرامها را تولید میکنند الگوریتمهایی با شدت محاسباتی خیلی بالا را استفاده میکنند، زیرا مسئله کلادوگرام انپی سخت میباشد.
مرحله۳: انتخاب بهترین کلادوگرام
چندین الگوریتم برای مشخص کردن بهترین کلادوگرام وجود دارد. بیشتر الگوریتمها یک metric را برای اندازهگیری اینکه چقدر یک کلادوگرام با دادههایش پایدار میباشد را اندازهگیری مینماید. بیشتر الگوریتمهای کلادوگرام تکنیکهای ریاضی optimization وminimization را استفاده مینمایند. در حالت معمول الگوریتمهای تولید کلادوگرام بایستی به صورت برنامههای کامپیوتری اجرا گردند، اگرچه تعدادی از الگوریتمها میتوانند به صورت دستی هنگامی که تعداد داده بدیهی میباشند بدست آیند. تعدادی از الگوریتمها وقتی که دادههای کامپیوتری مولکولی (DNA,RNA) میباشند مفید هستند؛ و تعدادی هنگامی که دادههای کاراکتری مورفولوژیک هستند مفید میباشند؛ و بعضی دیگر از الگوریتمها هنگامی که دادهها به صورت مولکولی یا مورفولوژی میباشند مفید هستند. الگوریتمها برای کلادوگرام کمترین مربعات، اتصال-همسایگی، تیغ اوکام، درستنمایی بیشینه، واستنباط بیزی را شامل میباشند. بیولوژیستها اکثر مواقع اصطلاح تیغ اوکام را برای یک نوع مشخص از الگوریتمهای تولید کلادوگرام و گاهی اوقات به عنوان یک واژه جامع برای تمام الگوریتمهای کلادوگرام استفاده میشود. الگوریتمهایی که وظایف بهینهسازی را انجام میدهند (همانند ایجاد کلادوگرامها) میتوانند حساس به اندازه دادههای ورودی (لیست گونهها و کاراکتر هایشان) که نمایش داده شدهاست باشند. واردکردن ورودی در واحدهای زمانی متفاوت میتواند منجر به این گردد که الگوریتمهای مشابه بهترین کلادوگرامها ی متفاوت را تولید نمایند. در این حالت کاربر بایستی ورودی را در واحدهای زمانی متفاوت وارد نماید و نتایج را مقایسه کند. استفاده از داده متفاوت روی داده یکسان میتواند گاهی بهترین کلادوگرامهای متفاوت را تولید نماید، زیرا ممکن است هر کدام تعریف مشخصی از بهترین را داشته باشند. بعلت تعداد نجومی از کلادوگرامهای ممکن، الگوریتمها نمیتوانند گارانتی کنند که جواب در کل بهترین جواب میباشد. یک کلادوگرام غیر بهینه اگر برنامه روی یک مینیمم محلی در عوض مینیمم سراسری قرارداده شده باشد انتخاب گردد. برای حل کردن این مسئله تعدادی از الگوریتمهای کلادوگرام رویکرد الگوریتم تبرید شبیهسازی شده را استفاده میکنند.
