مرتبسازی شل
مرتبسازی شِل یکی از قدیمیترین الگوریتمهای مرتبسازی و تعمیمی از مرتبسازی درجی با در نظر گرفتن دو نکته زیر است:
- الگوریتم مرتبسازی درجی درصورتی کارآمد است که دادهها تقریباً مرتب باشند.
- مرتبسازی درجی معمولاً کم بازدهاست چون مقادیر را در هر زمان فقط به اندازه یک موقعیت جابجا میکند.
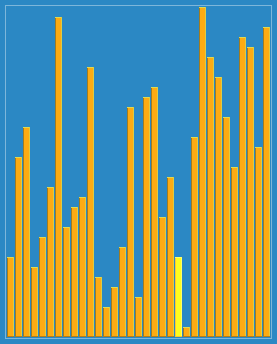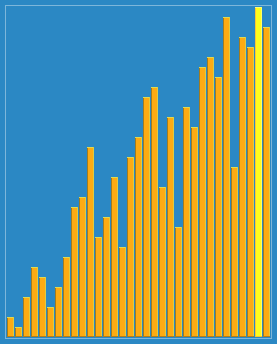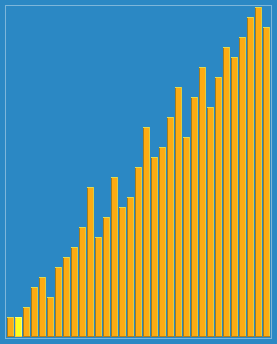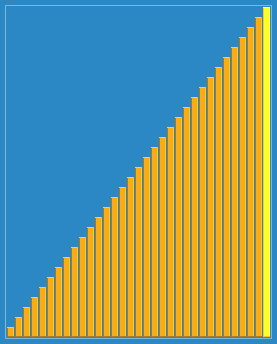 مرتبسازی شل با فاصلههای ۲۳، ۱۰، ۴، ۱ در عمل. | |
| رده | الگوریتم مرتبسازی |
|---|---|
| ساختمان داده | آرایه |
| کارایی بهترین حالت | O(n log2 n) |
| کارایی متوسط | O(n2) |
| پیچیدگی فضایی | О(n) عمومی، O(1) انباره |
مرتبسازی صدفی، الگوریتمی سریع و کارآمد و در عین حال یادگیری و پیادهسازی آن ساده است.
البته این نکته قابل توجه است که مرتبسازی صدفی درحقیقت به تنهایی دادهها را مرتب نمیکند بلکه به نوعی از سایر مرتبسازیها استفاده کرده و با یک دستهبندی مناسب که موجب میشود تعداد دفعاتی که هر داده بررسی میشود کاهش یابد، کارایی آنها را افزایش میدهد.

تاریخچه
این مرتبسازی به نام مخترعش، دونالد شِل[1] که این الگوریتم را در سال 1995 منتشر کرد نامگذاری شدهاست. برخی کتابها و منابع قدیمی تر این الگوریتم را «شل- مِتزنِر»[2] نیز نامیدهاند ولی طبق گفتهٔ خود مارلین متزنر (Marlene Metzner) «من هیچ کاری برای این الگوریتم انجام ندادم و اسم من هیچ وقت نباید به آن اضافه میشد» نام آن به شِل تغییر یافت.
کارایی زمانی

در روش مرتبسازی درجی در بدترین حالت الگوریتم از (O(n ۲ است درحالی که با مرتبسازی صدفی این زمان به (O(n log۲ کاهش یافتهاست.
در مرتبسازی صدفی، ابتدا دادهها در گامهای بزرگتری جابه جا میشوند اما در هر مرحله فاصله این جابه جاییها کم تر شده و به جابه جاییهای جزئی میرسد.
پیادهسازی
در این الگوریتم از روش مرتبسازی درجی استفاده میشود. به عبارتی ابتدا لیست را به چند دسته تقسیم میکند و هر کدام را جداگانه مرتب میکند. برای مثال اگر در ابتدا به ۳ دسته تقسیم کند، هر دسته را جداگانه به روش درجی که گفته شد، مرتب میکند. در هر مرحله، تعداد دستهها نصف میشود (دستهها بر اساس باقیمانده شان یا همان دستههای هم نهشتی). این عمل را ادامه میدهد تا سرانجام، تنها یک دسته شامل کل لیست داشته باشیم.
به عنوان مثال رشته f d a c b e را تحت این الگوریتم مرتب میکنیم.
کد:
F d a c b e: شروع
c b a f d e: مرحله اول a b c e d f: مرحله دوم a b c d e f: نتیجه
در مرحله اول دادههای با فاصله ۳ از یکدیگر، مقایسه و مرتب شده، در مرحله دوم دادههای با فاصله ۲ از یکدیگر، مقایسه و مرتب میشوند و در مرحله سوم دادهها با فاصله یک از یکدیگر مقایسه و مرتب میشوند.
منظور از فاصله سه این است که عنصر اول با عنصر چهارم(۳+۱)، عنصر دوم با عنصر پنجم(۵=۳+۲) و عنصر سوم با عنصر ششم(۶=۳+۳) مقایسه شده در جای مناسب خود قرار میگیرد.
برای انتخاب فاصله در اولین مرحله، تعداد عناصر لیست بر ۲ تقسیم میشود(n/۲) و فاصله بعدی نیز با تقسیم فاصله فعلی بر ۲ حاصل میگردد و الگوریتم تا زمانی ادامه پیدا میکند که این فاصله به صفر برسد. برای نمونه اگر تعداد عناصر برابر با ۱۰ باشد، فاصله در مرحله اول برابر با ۵، در مرحله دوم برابر با ۲ ور در مرحله سوم برابر با ۱ و در نهایت برابر با صفر خواهد بود.
حال به عنوان یک مثال عددی، مثال زیر را در نظر بگیرید:
فرض کنید لیستی مانند لیست روبرو داریم که میخواهیم با استفاده از این الگوریتم آن را مرتب کنیم : [ ۱۳ ۱۴ ۹۴ ۳۳ ۸۲ ۲۵ ۵۹ ۹۴ ۶۵ ۲۳ ۴۵ ۲۷ ۷۳ ۲۵ ۳۹ ۱۰ ]. حال اگر ما با یک گام (دستهبندی) ۵ تایی شروع کنیم، جدولی با ۵ ستون خواهیم داشت که صورت زیر خواهد بود:
۱۳ ۱۴ ۹۴ ۳۳ ۸۲ ۲۵ ۵۹ ۹۴ ۶۵ ۲۳ ۴۵ ۲۷ ۷۳ ۲۵ ۳۹ ۱۰
حال اگر هر ستون را مرتب کنیم، خواهیم داشت:
۱۰ ۱۴ ۷۳ ۲۵ ۲۳ ۱۳ ۲۷ ۹۴ ۳۳ ۳۹ ۲۵ ۵۹ ۹۴ ۶۵ ۸۲ ۴۵
برای اولین فراخوانی لیست رویرو را خواهیم داشت: [ ۱۰ ۱۴ ۷۳ ۲۵ ۲۳ ۱۳ ۲۷ ۹۴ ۳۳ ۳۹ ۲۵ ۵۹ ۹۴ ۶۵ ۸۲ ۴۵ ]. در اینجا عدد ۱۰ که در ابتدای لیست بود، به انتهای لیست آورده شدهاست. سپس لیست با استفاده از یک دسته بنده ۳ تایی و پس از آن یک دستهبندی ۱ تایی بوسیله مرتبسازی درجی مرتب خواهد شد.
پیادهسازی اصلی در بدترین حالت (O(n ۲ مقایسه و جابجایی انجام میدهد.
نوع دیگری از این الگوریتم با پیچیدگی کمتر نیز پیادهسازی شده که آن را به (O(n log۲ n ارتقا دادهاست ولی هنوز هم پیچیدگی این الگوریتم بدتر از بقیه مرتبسازیهای مقایسهای است که در (O(n log n عمل میکنند.
مرتبسازی شِل با مقایسهٔ عناصری که با یک فاصله (gap) از چندین مکان، جدا هستند مرتبسازی درجی را ارتقا میدهد.
این عمل باعث میشود که یک عنصر «قدمهای بزرگتری» به سمت مکان نهایی خود بردارد. گذرهای چند گانه روی اطلاعات با کوچک و کوچکتر کردن اندازههای فاصلهها انجام میشوند. آخرین مرحلهٔ مرتب شِل شامل یک مرتبسازی درجی سادهاست ولی بعد از آن میتوانیم مطمئن باشیم که آرایهٔ دادهها تقریباً مرتب شدهاست.
یک مقدار کوچک را که بهطور اولیه در انتهای غلط آرایه قرار گرفتهاست را در نظر بگیرید.
با استفاده از یک مرتبسازی (O(n ۲ مثل مرتبسازی حبابی یا درجی، باید n مقایسه و جابجایی انجام دهیم تا این مقدار را روی کل آرایه تا انتهای دیگر آن جابجا کنیم. مرتبسازی شِل ابتدا مقادیر را با استفاده از قدمهای بسیار بزرگ جابجا میکند، پس یک عنصر کوچک با چند مقایسه و جابجایی جزئی، مقدار زیادی از مسیر به سمت موقعیت نهایی خود را میپیماید.
عملکرد مرتبسازی شِل را میتوان به این صورت تصور کرد: تغییر لیست به یک جدول و مرتب کردن ستونها (با استفاده از مرتبسازی درجی)، تکرار مرحله قبل، هر دفعه با تعداد کمتری از ستونهای دراز تر. در نهایت جدول فقط یک ستون خواهد داشت که همان لیست مرتب شده نهایی است.
تبدیل لیست به جدول برای راحت تر تصور کردن نحوه انجام مرتبسازی است در حالی که خود الگوریتم، مرتبسازی را درجا انجام میدهد (با افزایش ضریب با استفاده از اندازهٔ گام).
برای مثال لیستی از اعداد به صورت {۱۳, ۱۴, ۹۴, ۳۳, ۸۲, ۲۵, ۵۹, ۹۴, ۶۵, ۲۳, ۴۵, ۲۷, ۷۳, ۲۵, ۹۳, ۱۰} را در نظر بگیرید. اگر اندازه قدم را ۵ در نظر بگیریم میتوان این گونه تصور کرد که لیست را به یک جدول با ۵ ستون تبدیل کردهایم؛ که به صورت زیر خواهد بود:
۱۳ ۱۴ ۹۴ ۳۳ ۸۲ ۲۵ ۵۹ ۹۴ ۶۵ ۲۳ ۴۵ ۲۷ ۷۳ ۲۵ ۳۹ ۱۰
سپس هر ستون را مرتب میکنیم، که خواهیم داشت:
۱۰ ۱۴ ۷۳ ۲۵ ۲۳ ۱۳ ۲۷ ۹۴ ۳۳ ۳۹ ۲۵ ۵۹ ۹۴ ۶۵ ۸۲ ۴۵
اگر این جدول را مثل لیستی از اعداد از انتها بخوانیم خواهیم داشت، {۱۰, ۱۴, ۷۳, ۲۵, ۲۳, ۱۳, ۲۷, ۹۴, ۳۳, ۳۹, ۲۵, ۵۹, ۹۴, ۶۵, ۸۲, ۴۵} که در آن عدد ۱۰ که در لیست اولیه در انتها قرار داشت به ابتدای لیست آمدهاست. این لیست دوباره با یک مرتبسازی سه فاصلهای و در نهایت یک مرتبسازی یک فاصلهای (مرتبسازی درجی ساده) مرتب خواهد شد.
ایده و طرز کار این الگوریتم به صورت زیر است:
- چیدن دنباله دادهها در یک آرایه دو بعدی
- مرتبسازی ستونهای آرایه
با این کار، دنباله دادهها اندکی مرتب میشود و سپس عملیات بالا مجدداً تکرار میشود ولی این بار با آرایهای کوچکتر. تا در نهایت در مرحله آخر به آرایهای تنها با یک ستون میرسد.
به عنوان مثال برای مرتبسازی دادههای { ۲ ۸ ۹ ۴ ۳ ۷ ۵ ۱ ۶ ۰ ۲ ۴ ۸ ۶ ۱ ۵ ۰ ۹ ۷ } با این روش، ابتدا دادهها در چند ستون (مثلاً در این جا در ۷ ستون) قرار داده میشود و سپس هر ستون به صورت مجزا مرتب میشود:
۳ ۷ ۹ ۰ ۵ ۱ ۶ ۳ ۳ ۲ ۰ ۵ ۱ ۵ ۸ ۴ ۲ ۰ ۶ ۱ ۵ -> ۷ ۴ ۴ ۰ ۶ ۱ ۶ ۷ ۳ ۴ ۹ ۸ ۲ ۸ ۷ ۹ ۹ ۸ ۲
در مرحله بعد:
۳ ۳ ۲ ۰ ۰ ۱ ۰ ۵ ۱ ۱ ۲ ۲ ۵ ۷ ۴ ۳ ۳ ۴ ۴ ۰ ۶ -> ۴ ۵ ۶ ۱ ۶ ۸ ۵ ۶ ۸ ۷ ۹ ۹ ۷ ۷ ۹ ۸ ۲ ۸ ۹
دنباله فاصلهها
دنباله فاصلهها یک قسمت کامل از مرتبسازی شِل میباشد. هر دنباله افزایشی ای میتواند در آن مورد استفاده قرار بگیرد به شرطی که آخرین عنصر افزاینده آن ۱ باشد. الگوریتم با انجام یک مرتبسازی درجی فاصلهای شروع به کار میکند که فاصله در آن اولین عدد موجود در دنباله فاصلهها میباشد. سپس با انجام مرتبسازی درجی فاصلهای با استفاده از هر عدد موجود در دنبالهٔ فاصلهها به کار خود ادامه میدهد تا آنجا که فاصله به مقدار ۱ برسد. وقتی که مقدار فاصله ۱ باشد مرتبسازی فاصلهای به سادگی یک مرتبسازی درجی معمولی است که ضمانت میکند که لیست نهایی مرتب شدهاست.
دنباله فاصلهای اصلی که توسط خود دونالد شِل پیشنهاد شد از شروع میشود و همین طور آنقدر عدد را نصف میکند تا به ۱ برسد. این دنباله کارایی فوقالعادهای برای الگوریتمهای چهارتایی مثل مرتبسازی درجی فراهم میکند، ولی به کمی تغییر میتوان زمان اجرای متوسط و بدترین حالت آن را باز هم بهبود بخشید. درکتاب مرجع وایس (Weiss) نشان داده شدهاست که اگر داده اولیه یک آرایه به صورت {کوچک اول، بزرگ اول، کوچک دوم، بزرگ دوم و...} باشد که در آن نیمهٔ بالایی اعداد در موقعیت مرتب شده در خانههای زوج و نیمهٔ پایینی اعداد به همین صورت در خانههای فرد قرار گرفته باشند، این دنباله یک مرتبسازی با بدترین زمان اجرای را تولید خواهد کرد.
شاید مهمترین ویژگی مرتبسازی شِل این باشد که حتی با کم و کم تر شدن فاصلهها عناصر به صورت k- مرتب شده باقی میمانند. برای مثال اگر لیستی در ابتدا ۵- مرتب شده باشد و آن را ۳- مرتبسازی کنیم آنگاه لیست نه تنها ۳- مرتب شدهاست، بلکه ۳ و ۵- مرتب شده نیز میباشد. اگر این درست نبود الگوریتم عملیاتی که در تکرارهای قبلی انجام دادهاست را خنثی میکند و دوباره از اول شروع به کار میکند و چنین زمان اجرای پایینی نخواهد داشت.
بسته به نوع دنباله فاصله انتخاب شده، ثابت شدهاست که مرتبسازی شِل دارای بدترین زمان اجرای (با استفاده از افزایندههای شِل که ۱/۲ اندازه آرایه هستند و هر بار نصف میشوند)، (با استفاده از افزایندههای هیباردِ )،
(با استفاده از افزایندههای سِدگِویکِ
یا)، یا
(با استفاده از افزایندههای پرَتِ )، و احتمالاً زمانهای اجرای بهتر و اثبات نشدهای، میباشد.
همچنین توسط پونن (Poonen)، پلکستون(Plaxton) و سوئل(Suel) اثبات شد که بدترین حالت مرتبسازی شِل به صورت
وجود ندارد.
بهترین دنباله با استناد به تحقیقات Marcin Ciura دنبالهٔ {۱, ۴, ۱۰, ۲۳, ۵۷, ۱۳۲, ۳۰۱, ۷۰۱, ۱۷۵۰} میباشد. این تحقیقات همچنین نتیجه میدهند که در مرتبسازی شِل مقایسهها، به جای جابجایی، باید عملکرد غالب در نظر گرفته شوند. مرتبسازی شِل با استفاده از این دنباله از مرتبسازی درجی، یا هیپ سریع تر اجرا میشود و با این حال که در آرایههای کوچک، از مرتبسازیسازی سریع نیز سریع تر عمل میکند، در آرایههای به قدر کافی بزرگ از آن باز میماند.
بعد از ۱۷۵۰ در دنباله بالا، فاصلههایی با پیشروی هندسی میتوانند مورد استفاده قرار بگیرند. مثل:
nextgap = round(gap * ۲٫۲)
یک دنبالهٔ دیگر که به صورت تجربی بهتر عمل میکند دنبالهٔ اعداد فیبوناچی (بدون یکی از ۱های اولیه) دو بار به توان عدد طلایی است، که دنبالهٔ زیر را ناشی میشود:
{۱, ۹, ۳۴, ۱۸۲, ۸۳۶, ۴۰۲۵, ۱۹۰۰۱, ۹۰۳۵۸, ۴۲۸۴۸۱, ۲۰۳۴۰۳۵, ۹۶۵۱۷۸۷, ۴۵۸۰۶۲۴۴, ۲۱۷۳۷۸۰۷۶, ۱۰۳۱۶۱۲۷۱۳, …}










شبه کد الگوریتم
استفاده از دنبالهٔ فاصلههای Marcin Ciura با یک مرتبسازی درجی داخلی:
# Sort an array a[0...n-1].
gaps = [701, 301, 132, 57, 23, 10, 4, 1]
# Start with the largest gap and work down to a gap of 1
foreach (gap in gaps)
{
# Do a gapped insertion sort for this gap size.
# The first gap elements a[0..gap-1] are already in gapped order
# keep adding one more element until the entire array is gap sorted
for (i = gap; i < n; i += 1)
{
# add a[i] to the elements that have been gap sorted
# save a[i] in temp and make a hole at position i
temp = a[i]
# shift earlier gap-sorted elements up until the correct location for a[i] is found
for (j = i; j >= gap and a[j - gap] > temp; j -= gap)
{
a[j] = a[j - gap]
}
# put temp (the original a[i]) in its correct location
a[j] = temp
}
}
مرتبسازی صدفی موازی
استفاده از روش حل و تقسیم در مورد الگوریتم مرتبسازی صدفی به خوبی جواب میدهد.
در هر مرحله از مرتبسازی، میتوان آرایه اصلی را به چند زیر آرایه که با یکدیگر تداخل نداشته باشند تقسیم کرد و هرکدام را بهطور مجزا مرتب نمود و در نهایت این آرایههای مرتب شده را در هم ادغام کرد.
پانویسها
- Donald Shell
- Shell-Metzner
منابع
پیوندهای خارجی
- http://www.csse.monash.edu.au/~lloyd/tildeAlgDS
- http://www.itl.nist.gov/div897/sqg/dads
- http://www.bgbm.org/CDEFD/CollectionModel/dsd.htm
- Shell Sort
- shell sort
| تئوری |  | |
|---|---|---|
| گونههای تعویضی | ||
| گونههای انتخابی | ||
| گونههای درجی | ||
| گونههای ادغامی | ||
| گونههای توزیعی | ||
| گونههای همرو | ||
| گونههای دوگانه |
| |
| گونههای دیگر |
| |
