مرتبسازی روان
مرتبسازی روان یک روش مرتبسازی بر پایهٔ مقایسه است. این مرتبسازی حالتی از مرتبسازی درهم است که توسط ادسخر دیکسترا در سال ۱۹۸۱ توسعه یافتهاست. مثل مرتبسازی درهم کران بالای مرتبسازی روان است. مزیت مرتبسازی روان این است که وقتی تعدادی از ورودیها مرتب شده باشد پیچیدگی از شود در حالی که متوسط پیچیدگی مرتبسازی روان است بدون توجه به مرتب بودن یا نبودن ورودیها


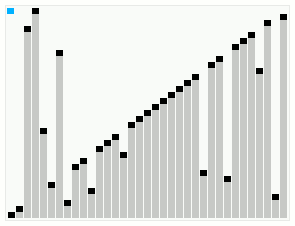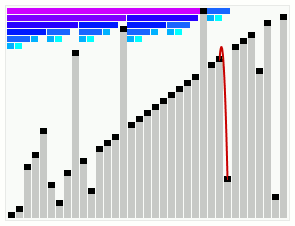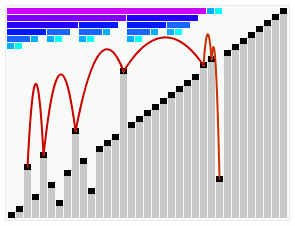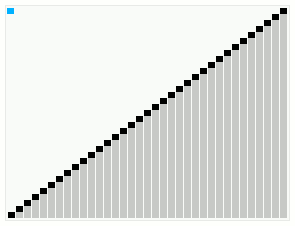 یک اجرا از الگوریتم مرتبسازی روان که یک آرایه مرتب اما با چند عنصر خارج از ترتیب را مرتب میکند. یک اجرا از الگوریتم مرتبسازی روان که یک آرایه مرتب اما با چند عنصر خارج از ترتیب را مرتب میکند. | |
| رده | الگوریتم مرتبسازی |
|---|---|
| ساختمان داده | آرایه |
| کارایی بدترین حالت | |
| کارایی بهترین حالت | |
| کارایی متوسط | |
| پیچیدگی فضایی | مجموع، کمکی |



بررسی اجمالی
برای اینکه یک آرایه را مرتب کنیم ابتدا آن را به رشتهای از پشتهها تقسیم میکنیم که هر پشته اندازه ی مساوی یکی از اعداد فیبوناچی دارد. فرایند تقسیم سادهاست -چپترین گرهٔ آرایه بزرگترین پشته ممکن را ایجاد میکند و بقیهٔ عناصر باقیمانده هم به همین شکل تقسیم شوند.
- هر آرایهای با هر طول میتواند به بخشهایی با اندازه تقسیم شود
- توضیح: مثلاً در کوچکترین حالت است
- هیچ دو پشتهای طول یکسان نخواهند داشت. این رشته یک رشته با طول اکیداً نزولی از پشتهها است هم چنین یک بیت از آرایه را میتوانیم برای نگه داشتن که به عنوان اندازه پشتهها استفاده میشود در نظر بگیریم.
- توضیح: به آرامی به سمت 2n افزایش مییابد پس در نتیجه در هر آرایهای همیشه یک وجود دارد که از نصف اندازه آرایه بزرگتر است.برای آرایه به اندازه ۲ استثنا وجود دارداما این آرایه را میتوانیم به ۲ آرایه با اندازه ۱ و 0 ( و ) تقسیم کنیم که هر ۲ با عدد ۱ تعریف شوند و برابر ۱ هستند.
- هیچ دو پشتهی طولی با های متوالی و پیاپی نخواهند داشت به جز دو عدد آخر که ممکن است چنین حالتی داشته باشند.
- اگر هیچ عنصری در چپ وجود نداشته باشد (حتی یک تک عنصر) بعد از بکار بردن دو و (متوالی) ما میتوانیم این دو را ترکیب کنیم و عنصری بزرگتر با نام بسازیم و اگر ما این کار را انجام ندهیم (ترکیب) بعد از و هیچ عنصر دیگری وجود نخواهد داشت. هر پشته دارای عنصری بنام اندازه اندازه است که از چپ به راست مثل یک پشته تفاضلی سازمان دهی شدهاست و به ترتیب از چپ به راست دارای عنصرهای و ویک گرهٔ ریشهاست که ابتدا برای پشتهها با طول و استثنا دارد (چون و برابر ۱ هستند).









هر پشته این خاصیت پشته را که گرهٔ ریشه همیشه بزرگتر مساوی گرههای فرزند آن ریشهاست را نگه میدارد و ریشهٔ پشتهها تمام این خاصیت را که گرهٔ ریشه در هر پشته بزرگتر مساوی گرهٔ ریشهٔ پشته چپ آن است را نگه دارد. نتیجه این است که راستترین گره در ریشه همیشه از بقیهٔ گرهها بزرگتر مساوی خواهد بود و مهمتر از همه اینکه آرایهای که اکنون مرتب شده برای اینکه مجموعهٔ معتبری از پشتهها شود نیازی به باز آرایی ندارد. الگوریتم سادهاست. ما با تقسیم آرایهٔ مرتب نشده به یک پشته از یک عنصر آغاز میکنیم.
مثل بخش مرتب نشده. یک آرایهٔ تک عنصر یک دنبالهٔ معتبری از پشتهها است. این دنباله بوسیلهٔ اضافه کردن عنصر به راست پشته افزایش مییابد (بزرگ میشود) و بوسیلهٔ جابجا کردن عناصر (swap) خاصیت دنبالهای و خاصیت پشتهای حفظ شود. از این نکات میفهمیم که راستترین عنصر هر دنبالهای از پشتهها بزرگترین عنصر آن پشتهاست و بنابراین هر عنصر سر جای اصلی خود قرار دارد
عملیات
یک لحظه الگوریتم بهینهسازی ادسخر دیکسترارا نادیده بگیرید. دو عملیات لازم است.
- افزایش رشته بوسیله اضافه کردن عنصر به راست عناصر موجود
- کاهش رشته بوسیلهٔ حذف کردن راستترین عنصر (ریشهٔ هیپ قبلی) و حفظ و ذخیرهٔ هیپ و موقعیت رشته
افزایش رشته بوسیله اضافه کردن عنصر به راست اگر مثلاً آخرین ۲ هیپ به سایزهای و باشد عنصر جدیدی که اضافه کنیم گرهٔ ریشهٔ یک هیپ بزرگتر به سایز شود که این هیپ لازم ندارد که خاصیت هیپ را داشته باشد. اگر مثلاً آخرین دو هیپ متوالی نبودند بعد از راستترین عنصر یک هیپ جدید به سایز ۱ ایجاد میشود که در حقیقت این همان هست. پس در نتیجه در این حالت راستترین هیپ اکنون سایز دارد. بعد از این خصوصیات رشته و هیپ باید ذخیره شود به شکل زیر این کار انجام شود:
- راستترین هیپ را به عنوان (current)هیپ انتخاب کنیم.
- در این حالت در چپ هیپ (current)یک هیپ وجود دارد که از ریشهٔ current بزرگتر است و هر دوی آنها در پایان بچهٔ هیپ ریشه هستند سپس ریشهٔ جدید را با ریشهٔ هیپ چپ جابجا کنید. حالا در نتیجه آن هیپ، هیپ current میشود.
- یک عملیات فیلتر را روی هیپ current برای ایجاد خواص هیپ انجام دهید. در حالی که هیپ current سایز بزرگتر از ۱ و بقیهٔ بچهها ی خود داشته باشد. یک گرهٔ ریشه بزرگتر از ریشهٔ current هیپ دارد حالا بچهٔ بزرگتر ریشه را با ریشهٔ current جابجا کنید. آن هیپ بچهٔ هیپ current میشود.
بهینهسازی : اگر هیپ جدید قصد دارد قسمتی از هیپ بزرگتر شود خودتان را برای ایجاد رشتهٔ خصوصیات زحمت ندهید. این کار فقط وقتی لازم است که یک هیپ در دسترس است و تنها کاری که میکند سایز نهایی را میدهد. بعد از اینکه این کار انجام شد نگاه کنید چگونه بسیاری از عناصر، چپ هیپ جدید به سایز هستند حال اگر هیپی با مقدار 1+ وجود داشت این هیپ ادغام میشود. خصوصیات هیپ را در راستترین هیپ ذخیره نکنید، اگر حالا آن هیپ یکی از هیپهای نهایی رشته شود سپس خصوصیات رشته را ذخیره کنید. البته هر موقع که یک هیپ چدید ایجاد میشود بعد از اضافه شدن، راستترین هیپ جدید از راستترین هیپ قبل بزرگتر نیست و خصوصیات هیپ نیاز دارند ذخیره شوند. کاهش رشته بوسیله حذف راستترین عنصر اگر راستترین عنصر سایز ۱ دارد دیگر هیچ کاری لازم نیست انجام دهید. به سادگی راستترین هیپ را حذف کنید. اگر راستترین هیپ سایز ۱ نداشت سپس ریشه را حذف کنید سپس ۲ هیپ قبلی (sub-heap)را مثل عضوهای رشته نمایش دهید. خصوصیات رشته را ابتدا در چپترین و سپس در راستترین عنصر ذخیره کنید بهینهسازی موقعی که خصوصیات رشته را ذخیره میکنیم به مقایسهٔ ریشهٔ هیپ چپ با دو گرهٔ بچه هیپی که فقط نمایش داده شدهاست نیاز نداریم زیرا ما میدانیم که این هیپها دارای خصوصیات هستند و فقط آن را با ریشه مقایسه کنیم
پیادهسازی در جاوا
در این کد دو متغیر lo وhi به عنوان ۲ کران بالا و پایین استفاده شده است
// by keeping these constants, we can avoid the tiresome business
// of keeping track of Dijkstra's b and c. Instead of keeping
// b and c, I will keep an index into this array.
static final int LP[] = { 1, 1, 3, 5, 9, 15, 25, 41, 67, 109,
177, 287, 465, 753, 1219, 1973, 3193, 5167, 8361, 13529, 21891,
35421, 57313, 92735, 150049, 242785, 392835, 635621, 1028457,
1664079, 2692537, 4356617, 7049155, 11405773, 18454929, 29860703,
48315633, 78176337, 126491971, 204668309, 331160281, 535828591,
866988873 // the next number is> 31 bits.
};
public static <C extends Comparable<? super C>> void sort(C[] m,
int lo, int hi) {
int head = lo; // the offset of the first element of the prefix into m
// These variables need a little explaining. If our string of heaps
// is of length 38, then the heaps will be of size 25+9+3+1, which are
// Leonardo numbers 6, 4, 2, 1.
// Turning this int a binary number, we get b01010110 = x56. We represent
// this number as a pair of numbers by right-shifting all the zeros and
// storing the mantissa and exponent as "p" and "pshift".
// This is handy, because the exponent is the index into L[] giving the
// size of the rightmost heap, and because we can instantly find out if
// the rightmost two heaps are consecutive leonardo numbers by checking
// (p&3)==3
int p = 1; // the bitmap of the current standard concatenation>> pshift
int pshift = 1;
while (head <hi) {
if ((p & 3) == 3) {
// Add 1 by merging the first two blocks into a larger one.
// The next Leonardo num is one bigger.
sift(m, pshift, head);
p>>>= 2;
pshift += 2;
} else {
// adding a new block of length 1
if (LP[pshift - 1]>= hi - head) {
// this block is its final size.
trinkle(m, p, pshift, head, false);
} else {
// this block will get merged. Just make it trusty.
sift(m, pshift, head);
}
if (pshift == 1) {
// LP[1] is being used, so we add use LP[0]
p <<= 1;
pshift--;
} else {
// shift out to position 1, add LP[1]
p <<= (pshift - 1);
pshift = 1;
}
}
p |= 1;
head++;
}
trinkle(m, p, pshift, head, false);
while (pshift != 1 || p != 1) {
if (pshift <= 1) {
// block of length 1. No fiddling needed
int trail = Integer.numberOfTrailingZeros(p & ~1);
p>>>= trail;
pshift += trail;
} else {
p <<= 2;
p ^= 7;
pshift -= 2;
// ok. This block gets broken into three bits. The rightmost
// bit is a block of length 1. The left hand part is split into
// two, a block of length LP[pshift+1] and one of LP[pshift].
// Both these two are appropriately heapified, but the root
// nodes are not nessesarily in order. We therefore semitrinkle
// both
// of them
trinkle(m, p>>> 1, pshift + 1, head - LP[pshift] - 1, true);
trinkle(m, p, pshift, head - 1, true);
}
head--;
}
}
private static <C extends Comparable<? super C>> void sift(C[] m, int pshift,
int head) {
// we do not use Floyd's improvements to the heapsort sift, because we
// are not doing what heapsort does - always moving nodes from near
// the bottom of the tree to the root.
C val = m[head];
while (pshift> 1) {
int rt = head - 1;
int lf = head - 1 - LP[pshift - 2];
if (val.compareTo(m[lf])>= 0 && val.compareTo(m[rt])>= 0)
break;
if (m[lf].compareTo(m[rt])>= 0) {
m[head] = m[lf];
head = lf;
pshift -= 1;
} else {
m[head] = m[rt];
head = rt;
pshift -= 2;
}
}
m[head] = val;
}
private static <C extends Comparable<? super C>> void trinkle(C[] m, int p,
int pshift, int head, boolean isTrusty) {
C val = m[head];
while (p != 1) {
int stepson = head - LP[pshift];
if (m[stepson].compareTo(val) <= 0)
break; // current node is greater than head. Sift.
// no need to check this if we know the current node is trusty,
// because we just checked the head (which is val, in the first
// iteration)
if (!isTrusty && pshift> 1) {
int rt = head - 1;
int lf = head - 1 - LP[pshift - 2];
if (m[rt].compareTo(m[stepson])>= 0
|| m[lf].compareTo(m[stepson])>= 0)
break;
}
m[head] = m[stepson];
head = stepson;
int trail = Integer.numberOfTrailingZeros(p & ~1);
p>>>= trail;
pshift += trail;
isTrusty = false;
}
if (!isTrusty) {
m[head] = val;
sift(m, pshift, head);
}
}
منابع
ویکیپدیا انگلیسی
Commented transcription of EWD796a
http://www.cs.utexas.edu/users/EWD/ewd07xx/EWD796a.PDF
http://www.cs.utexas.edu/~EWD/transcriptions/EWD07xx/EWD796a.html
| تئوری |  | |
|---|---|---|
| گونههای تعویضی | ||
| گونههای انتخابی | ||
| گونههای درجی | ||
| گونههای ادغامی | ||
| گونههای توزیعی | ||
| گونههای همرو | ||
| گونههای دوگانه |
| |
| گونههای دیگر |
| |
| ادسخر دیکسترا |
| ||||
|---|---|---|---|---|---|
| علوم رایانه | |||||
| ادسخر دیکسترا |
| ||||
| Related people |
| ||||
| Other topics |
| ||||