مرتبسازی سریع
کوییکسورت (به انگلیسی: Quicksort)، یکی از الگوریتمهای مرتبسازی است که بهدلیل مصرف حافظه کم، سرعت اجرای مناسب و پیادهسازی ساده بسیار مورد قبول واقع شدهاست.
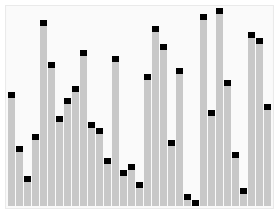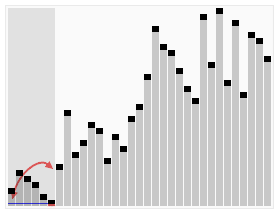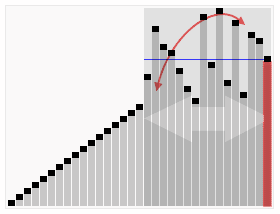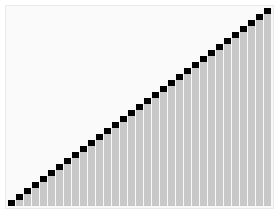 کارکرد مرتبسازی سریع بر روی یک فهرست تصادفی از اعداد. محور افقی اندازههای عناصر محوری هستند. | |
| رده | الگوریتم مرتبسازی |
|---|---|
| ساختمان داده | آرایه |
| کارایی بدترین حالت | |
| کارایی بهترین حالت | (تقسیمبندی ساده) یا (تقسیمبندی سه جانبه و کلیدهای برابر) |
| کارایی متوسط | |
| پیچیدگی فضایی | کمکی (ساده) کمکی (سجویک ۱۹۷۸) |




پیادهسازی
هر پیادهسازی این الگوریتم بهصورت کلی از دو بخش تشکیل شدهاست. یک بخش تقسیمبندی آرایه (partition) و قسمت مرتب کردن. روش مرتبسازی سریع (Quick Sort) یکی از الگوریتمهای مشهور مرتبسازی دادهها است. این الگوریتم طی مراحل بازگشتی زیر یک روش تقسیم و غلبه برای مرتب کردن دادهها ارائه مینماید:
۱- انتخاب عنصر محوری: یکی از عناصر آرایه به عنوان عنصر محوری (pivot) - به عنوان مثال عنصر اول - انتخاب میشود.
۲- تقسیم آرایه: چینش عناصر آرایه به قسمی تغییر داده میشود که تمامی عناصر کوچکتر یا مساوی محور در سمت چپ آن، و تمامی عناصر بزرگتر در سمت راست آن قرار بگیرند. این دو قسمت زیر آرایههای چپ و راست نامیده میشوند.
۳- مرتبسازی بازگشتی: زیرآرایههای چپ و راست به روش مرتبسازی سریع مرتب میشوند.
مثال
مراحل مختلف (Partion (1,10 را بر روی دادههای زیر بنویسید.
i، ۱، ۲، ۳، ۴، ۵، ۶، ۷، ۸، ۹، ۱۰، i، P
A[i]، ۶۵، ۷۰، ۷۵، ۸۰، ۸۵، ۶۰، ۵۵، ۵۰، ۴۵، ∞، ۲، ۹
جا به جایی ۴۵ با ۷۰:
۹ ،۲، ∞ ،۷۰ ،۵۰ ،۵۵ ،۶۰، ۸۵ ،۸۰ ،۷۵، ۴۵ ،۶۵
جا به جایی ۷۵ با ۵۰:
۸ ،۳، ∞ ،۷۰ ،۷۵ ،۵۵ ،۶۰ ،۸۵ ،۸۰ ،۵۰ ،۴۵ ،۶۵
جا به جایی ۸۰ با ۵۵:
۷ ،۴، ∞، ۷۰ ،۵۰ ،۸۰ ،۶۰ ،۸۵ ،۵۵ ،۷۵ ،۴۵ ،۶۵
جا به جایی ۸۵ با ۶۰:
۶ ،۵، ∞ ،۷۰ ،۵۰ ،۸۰ ،۸۵ ،۶۰ ،۵۵ ،۷۵ ،۴۵ ،۶۵
جا به جایی ۶۵ با ۶۰:
۵ ،۶، ∞ ،۷۰ ،۵۰ ،۸۰ ،۸۵ ،۶۵ ،۵۵ ،۷۵ ،۴۵ ،۶۰
الگوریتم انتخاب kامین عنصر کوچک آرایه [A[1..n
فرض کنید که بعد از فراخوانی الگوریتم Partition عنصر افراز در مکان j ام قرار بگیرد، در این صورت بدیهی است که j-1 عنصر آرایهٔ کوچکتر یا مساوی A[j] است و n-j عنصر باقیمانده بزرگتر یا مساوی آن خواهد بود؛ بنابراین سه حالت زیر امکانپذیر است:
اگر k<j آنگاه kامین عنصر کوچکتر آرایه در A[1...j-1] قرار دارد.
اگر k=j آنگاه A[j]، عنصر Kامین عنصر کوچکتر است.
اگر k>j آنگاه kامین عنصر کوچکتر آرایه برابر k-jامین عنصر کوچکتر آرایهٔ A[j+1...n] خواهد بود.
مطالب گفته شده توسط الگوریتم Selection در زیر ارائه شدهاست:
Algorithm Select (k)
m=1 , r=n+1 , A[n+1]= ∞
Loop
{
j=r
partition (m , j)
if k=j then Return(A[j])
else
if k<j then r=j
else m=j+1
}
شبه کد
آرایه[A[p..r، عنصر آخر هربار به عنوان pivot قرار میگیرد.
Partition(A,p,r)
x := A[r]
i := p - 1
for j := p to r-1
do if A[j]<=x
then i := i + 1
exchange A[i]<->A[j]
exchange A[i+1]<->A[r]
return i+1
quickSort(A,p,r)
if p<r
then q:=Partition(A,p,r)
quickSort(A,p,q)
quickSort(A,q+1,r)
پیادهسازی به زبان ++C
نمونهای از این پیادهسازی به زبان ++C به صورت زیر است.
void quicksort(int array[] , int left , int right){
if (left < right){
int middle = partition(array , left , right) ;
quicksort(array , left , middle-1) ;
quicksort(array , middle+1 , right);
}
}
int partition(int array[] , int left , int right){
int middle ;
int x = array[left] ;
int l = left ;
int r = right ;
while(l < r){
while((array[l] <= x) && (l < right)) l++ ;
while((array[r] > x) && (r >= left)) r-- ;
if(l < r){
int temp = array[l];
array[l] = array[r];
array[r] = temp ;
}
}
middle = r ;
int temp = array[left];
array[left] = array[middle] ;
array[middle] = temp;
return middle ;
}
پیادهسازی به زبان پاسکال
پیادهسازی مشابه ولی فشردهتر به زبان pascal به صورت زیر میتواند باشد
procedure Sort(l, r: Integer);
var
i, j, x, y: integer;
begin
i := l; j := r; x := a[(l+r) DIV 2];
repeat
while a[i] < x do i := i + 1;
while x < a[j] do j := j - 1;
if i <= j then
begin
y := a[i]; a[i] := a[j]; a[j] := y;
i := i + 1; j := j - 1;
end;
until i > j;
if l < j then Sort(l, j);
if i < r then Sort(i, r);
end;
و یا این سورس پاسکال که بیشتر به کد سی این مثال شبیه است:
Function partion(ilow, ihigh: Integer): Integer;
Var
i, j, temp, pivotitem: Integer;
Begin
QS_TC := QS_TC + (ihigh - ilow + 1);
pivotitem := C[ilow];
j := ilow;
For I := iLow + 1 To iHigh Do
If (c[i] < pivotitem) Then
Begin
Inc(j);
temp := c[i];
c[i] := c[j];
c[j] := temp;
End;
temp := c[ilow];
c[ilow] := c[j];
c[j] := temp;
Result := j;
End;
Procedure QuickSort(p, q: Integer);
Var
j: Integer;
Begin
If Not (p >= q) Then
Begin
j := partion(p, q);
QuickSort(p, j - 1);
QuickSort(j + 1, q);
End;
End;
پیادهسازی به صورت تصادفی
در این پیادهسازی به جای این که همیشه از[ A[r به عنوان عنصر محوری استفاده کنیم، از عنصری که بهطور تصادفی از زیر آرایهٔ [A[p..r انتخاب میشود استفاده میکنیم. این کار با تعویض عنصر [ A[r با عنصری که از [A[p..r بهطور تصادفی انتخاب میشود انجام میدهیم. این تغییر که در آن بهطور تصادفی از ادامه r...p یک نمونه انتخاب میکنیم، اطمینان میدهد که عنصر محوری [x= A[r با احتمال برابر میتواند هر یک از r-p+1 عنصر زیر آرایه باشد. چون عنصر محوری به شکلی تصادفی انتخاب میشود انتظار داریم تقسیمات آرایه ورودی در حالت میانگین به شکل مناسبی متوازن باشد. زمان اجرای مرتبسازی سریع به زمانی که در روال partition صرف میشود بستگی دارد. هر بار که روال partition فراخوانی میشود، یک عنصر محوری انتخاب میشود و این عنصر هیچگاه در فراخوانیهای بعدی مرتبسازی سریع و partition ظاهر نمیشود. بنابراین حداکثر n فراخوانی Partition در کل اجرای الگوریتم مرتبسازی سریع وجود دارد و یک فراخوانی Partition دارای زمان (O(1 به اضافه مقدار زمانی که متناسب با تعداد تکرارهای حلقه for در الگوریتم است. هر تکرار حلقه for یک مقایسه انجام میدهد، مقایسه بین عنصر محوری و عنصر دیگری از آرایه A. بنابراین اگر بتوانیم تعداد کل دفعاتی که این مقایسهها اجرا میشود را محاسبه کنیم، میتوانیم کل زمانی را که در حلقه for در طی اجرای کامل quickSort صرف میشود را محدود کنیم.
پیادهسازی صنعتی
الگوریتم مرتبسازی در دنیای واقعی برای آرایه نسبتاً کوچک مناسب نیست. به علاوه بخش پارتیشن خود نیز مشکل بزرگی در زمان اجرا میباشد. برای همین پیشنهاد میگردد برای آرایههایی از طول کمتر از ۷ از مرتبسازیهای دیگر مانند مرتبسازی درجی یا حبابی استفاده شود. به علاوه به جای پیادهسازی بخش partition به صورت عادی با احتمالاتی میتوان از میانه ۹ برای آرایههای بزرگ (بیش از ۴۰ درایه) و میانه ۳ برای ارایههای متوسط (کمتر از ۴۰ درایه) و عضو وسط برای آرایههای کوچک استفاده کرد. به علاوه در چنین پیادهسازیهایی ابتدا اعداد صفر (برای آرایه از اعداد مثبت) را ابتدا به شروع آرایه منتقل میکنند. و همچنین درایههای غیر عددی را نیز هندل میکنند تا در اجرای الگوریتم اختلالی به وجود نیاورد.
برای توضیحات بیشتر دربارهٔ نسخههای بهینه مرتبسازی سریع میتوانید به مرجع بنتلی و مک ایلوری مراجعه نمایید. پیادهسازی بسیار خوبی از این الگوریتم را میتوانید در کد منبع جاوا و در کلاس java.util.Array بیابید.
زمان اجرا
مرتبسازی سریع چه در پیادهسازی عادی و چه در پیادهسازی احتمالی در حالت متوسط در زمان اجرای اجرا میشود.

- بهترین حالت تقسیمبندی: رابطه بازگشتی در بهترین حالت دربارهٔ آن صدق میکند. در اکثر تقسیمات ممکن، Partition دو زیر مسئله ایجاد میکند که اندازهٔ هر یک از آنها بیش از n/2 نیست، در این حالت، مرتبسازی سریع خیلی سریع تر انجام میشود، لذا موازنه برابر دو طرف تقسیم در هر مرحله از بازگشت، الگوریتمی ایجاد میکند که بهطور مجانبی سریع تر است.
- بدترین حالت تقسیمبندی: بدترین حالت برای مرتبسازی سریع هنگامی رخ میدهد که روال تقسیمبندی یک زیر مسئله با n-1 عنصر و یک زیر مسئله با ۰ عنصر ایجاد کند. فرض کنیم که این تقسیمبندی نامتوازن در فراخوانی بازگشتی به وجود آید. تقسیمبندی زمان را صرف میکند. چون فراخوانی بازگشتی روی آرایهای با اندازهٔ ۰، دقیقا که همان است را برگردانده و رابطهٔ بازگشتی برای زمان اجرا به این صورت میباشد:. بهطور شهودی اگر هزینههای ایجاد شده در هر مرحله بازگشت را با هم جمع کنیم یک سری حسابی به دست میآوریم که برابر است؛ بنابراین زمان اجرای مرتبسازی سریع در بدترین حالت بهتر از مرتبسازی درجی نیست. علاوه بر این، زمان اجرای زمانی نیز که که آرایه ورودی از قبل مرتب باشد رخ میدهد، در شرایطی مشابه، مرتبسازی درجی در زمان اجرا میشود.
- اگر در هر سطح از بازگشت، تقسیمبندی که با استفاده از Randomized_Partition صورت گرفتهاست، کسر ثابتی از عناصر را در یک طرف تقسیمبندی قرار دهد، آن گاه عمق درخت بازگشت بوده و عمل در هر سطح انجام میشود. حتی اگر سطح جدیدی با نامتوازنترین تقسیمبندی ممکن را در بین این سطوح اضافه کنیم زمان کل، باقی میماند. میتوانیم ابتدا با دانستن چگونگی عملکرد روال تقسیمبندی و سپس با استفاده از آن برای به دست آوردن حد روی زمان اجرای مورد انتظار، زمان اجرایی که برای Randomized_QuickSort انتظار میرود را دقیق تر کنیم. این حد بالای زمان اجرای مورد انتظار در بدترین حالت زمان اجرای این الگوریتم است.







ویژگیهای مرتبسازی سریع
۱- پیچیدگی زمانی اجرای الگوریتم در بهترین حالت (Ө(n log n و در بدترین حالت (Ө(n2 است. با استفاده محاسبات ریاضی میتوان نشان داد در حالت متوسط نیز مرتبه اجرا (Ө(n log n است.
۲- این الگوریتم یک مرتبسازی درجا است. یعنی میزان حافظه مصرفی الگوریتم مستقل از طول آرایه است.
۳- زمانی که تعداد عناصر آرایه کم باشد، سرعت اجرای مرتبسازی درجی بهتر از مرتبسازی سریع است. به همین دلیل طی مراحل بازگشتی مرتبسازی سریع، اگر طول بازه عدد کوچکی باشد، معمولاً بازه با مرتبسازی درجی مرتب میشود.
۴- الگوریتم مرتبسازی سریع با پیادهسازی فوق یک روش ناپایدار است. چنین الگوریتمی لزوما ترتیب عناصر با مقدار یکسان را پس از مرتبسازی حفظ نمیکند.
۵- انتخاب عنصر محوری بحث مفصلی دارد. اما در کل یک انتخاب آزاد است. میتوان عنصر اول، عنصر آخر، یا هر عنصر دیگری را به عنوان عنصر محوری انتخاب کرد. حتی لازم نیست از ابتدا تا انتها از یک روش انتخاب استفاده کرد. یکی از روشهای رایج، انتخاب یک عنصر تصادفی به عنوان عنصر محوری است. اگرچه انتخاب عنصر محوری مناسب باعث بالا رفتن کارایی الگوریتم میشود، اما عموماً هزینه لازم برای یافتن چنین محوری بالا بوده و مقرون به صرفه نیست.
منابع
- D.E.Knuth «The Art of Computer Programming» Vol.۲
- Udi Manber , Introduction to Algorithms- A creative Approach
- CLRS , Introduction to Algorithms
- Jon L. Bentley and M. Douglas McIlroy's "Engineering a Sort Function
| تئوری |  | |
|---|---|---|
| گونههای تعویضی | ||
| گونههای انتخابی | ||
| گونههای درجی | ||
| گونههای ادغامی | ||
| گونههای توزیعی | ||
| گونههای همرو | ||
| گونههای دوگانه |
| |
| گونههای دیگر |
| |
