الگوریتم تطابق رشتهها
الگوریتمهای تطابق رشته ای، که گاهی الگوریتمهای جسیتجوی رشته ای گقته میشوند، دستهٔ مهمی از الگوریتمهای رشتهای هستند که سعی میکنند محل رخداد یک یا چند رشته (الگو) در یک رشتهٔ بزرگتر (یا متن) را پیدا کنند.
Σ را مجموعهٔ الفبای محدودی فرض کنید.معمولا، هم الگو و هم متن مورد نظر، ترکیبی از عناصرΣ میباشند. Σ میتواند یک الفبای انسانی معمولی باشد (مثلا، حروف A تا Z در زبان انگلیسی). در کاربردهای دیگر ممکن است از الفبای دودویی ({(Σ = {0,1) یا الفبای DNA در بیوانفورماتیک استفاده شود.
بهطور خاص، این که رشته چگونه رمز شدهاست میتواند روی الگوریتم ملموس تطابق، تأثیرگذار باشد. مخصوصاً اگر رمز نگاری طولی متغیر مورد استفاده قرار گیرد، به کندی میتوان کاراکتر N ام را پیدا کرد. این میتواند بهطور محسوسی الگوریتمهای جستجوی پیشرفته تر را کند، کند. یک راه حل این است که به دنبال دنبالهای از واحدهای رمز بگردیم، اما این روش ممکن است باعث ایجاد مطابقتهای اشتباه گردد. اگر رمز نگاری به گونهای خاص طراحی شده باشد، از این مشکل جلوگیری میشود.
تقسیم بندی کلی
الگوریتمهای مختلف را میتوان بر اساس تعداد الگوهایی که استفاده میکنند دسته بندی کرد.
الگوریتمهای تک الگویی
- الگوریتم جستجوی رشتهٔ نیو
- الگوریتم جستجوی رشتهٔ رابین-کارپ
- جستجو بر پایهٔ ماشینهای خودکار محدود حالته
- الگوریتم جستحوی رشتهای Boyer-MooreKnuth-Morris-Pratt
- لگوریتمBitap
الگوریتمهایی با مجموعه الگوهای متناهی
- الگوریتم Aho-Corasick
- الگوریتمCommentz-Walter
- الگوریتم جستجوی رشتهٔ رابین-کارپ
الگوریتمهای با تعداد الگوهای نامتناهی
طبیعتا در این حالت تعداد الگوها غیرقابل شمارش است. آنها را معمولاً با یک عبارت عادی نمایش میدهند.
دیگر تقسیم بندیها
تقسیم بندیهای دیگری نیز امکانپذیر است. یکی از رایجترین آنها پیش پردازش را به عنوان معیار در نظر میگیرد.
| متن پیش پردازش نشده | متن پیش پردازش شده | |
|---|---|---|
| الگوهای پیش پردازش نشده | الگوریتمهای ابتدایی | روشهای نمایه سازی |
| الگوهای پیش پردازش شده | موتورهای جستجوی ساخته شده | روشهای دستینه سازی |
جستجوی رشتهای naive
آسانترین و ناکارامدترین راه برای آنکه ببینیم کجا یک رشته در رشتهای دیگر تکرار شده، آن است که تمام مکانهای ممکن را یکی یکی بررسی کنیم.
در حالت نورمال، برای هر مکان اشتباه، فقط کافی است یک یا دو کاراکتر را چک کنیم پس در حالت متوسط، این O(n + m) مرحله طول میکشد، که n طول متن وm اندازهٔ کلمهٔ مورد جستجو(کلید) است; اما در بدترین حالت، جستجوی یک رشته مثل "aaaab" در یک رشته مثل "aaaaaaaaab", O(nm)مرحله طول میکشد.
جستجو بر اساس ماشینهای خودکار محدود حالته
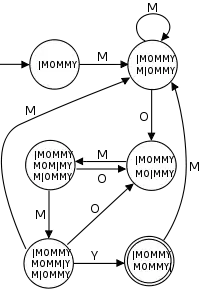
در این روش، با ساختن یکماشین محدود قطعی(deterministic) که رشتههایی را که حاوی رشتهٔ مطلوب مورد جستجو هستند، تشخیص میدهد. ساخت آنها هزینه بر است اما بسیار سربع هستند. مثلاً DFA که در سمت راست نشان داده شدهاست کلمهٔ "MOMMY" را تشخیص میدهد.این شیوه در عمل برای جستجوی عبارات معمولی دلخواه، عمومیت داده میشود.
نمونههایی دیگر
Knuth-Morris-Pratt یک ماشین محدود قطعی میسازد که پسوندی از رشتهٔ مورد نظر را جستجو کند کلید را از آخر در متن جستجو میکند تا بتواند در اکثر مواقع به اندارهٔ طول کلید در متن پرش کند. Baeza-Yates نگه میدارد که آیا کاراکترهای j قبلی پیشوندی از رشتهٔ مورد جستجو هستند یا نه، از این رو تطبیق پذیر با جستجوی رشتهای fuzzy میباشند. الگوریتم bitap کاربردی از روش Baeza-Yates' است.
روشهای نمایهای
الگوریتمهای سریع تر بر پایهٔ پیش پردازش متن کار میکنند. پس از ساخت نمایهٔ زیر رشته، مثلاً درخت پسوند یاآرایهٔ پسوند، رخدادهای یک الگو خیلی سریع یافت میشوند. به عنوان مثال، یک درخت پیشوند میتواند در زمان (Theta(m ساخته شود، و تمام رخدادهای یک الگو میتوانند در زمان (O(m+z یافت شوند (اگر اندازهٔ مجموعهٔ الفبا را یک ثابت در نظر بگیریم).

انواع دیگر
بعضی از روشهای جستجو، مثلاً جستجویtrigram، به منظور محاسبهٔ یک نمرهٔ شباهت بین دو رشته ساخته شدهاند و نه صرفا برای نشخیص "تطبیق با عدم تطبیق". این نوع را گاهی جسنجوی کرکی یا fuzzy میگویند.
پیوندها
مراجع
- R. S. Boyer and J. S. Moore, A fast string searching algorithm, Carom. ACM 20, (10), 262–272(1977).
- توماس اچ کورمن, Charles E. Leiserson, رونالد ریوست, and کلیفورد استین. مقدمهای بر الگوریتمها, Second Edition. MIT Press and McGraw-Hill, 2001. ISBN 0-262-03293-7. Chapter 32: String Matching, pp.906–932.
پیوندهای خارجی
- Huge (maintained) list of pattern matching links
- StringSearch – high-performance pattern matching algorithms in Java – Implementations of many String-Matching-Algorithms in Java (BNDM, Boyer-Moore-Horspool, Boyer-Moore-Horspool-Raita, Shift-Or)
- Exact String Matching Algorithms — Animation in Java, Detailed description and C implementation of many algorithms.
- String similarity metrics
- Boyer-Moore-Raita-Thomas